

دليل شامل للهندسة التوجيهية (Prompt Engineering)
في عالم الذكاء الاصطناعي اللي قاعد يتطور، ولى استعمال النماذج اللغوية الضخمة (LLMs) جزء أساسي من شغل الـ developers و الـ ML Engineers.
هوني يجي دور الـ Prompt Engineering، وين نتعلمو كيفاش نكتبوا التعليمات (prompts) بطريقة تخلي الـ LLMs تخرج نتائج دقيقة وذات معنى. ورغم أنو الـ LLMs تدربت على كميات كبيرة من الداتا، إلا أنو وضوح الـ prompts يزيد من دقة النتائج.
في المقالة هاذي، باش نكتشفو استراتيجيات الـ Prompt Engineering باش نحسنو أداء النماذج ونوسعو استعمالاتها.
ببساطة، هي فن كتابة الأسئلة أو التعليمات اللي بتوجه الـ LLMs، علشان نطلع منها النتيجة اللي نحبها. العملية هاذي تعتمد على شوية إرشادات لو اتبعناها صح، هتحسن بشكل كبير من جودة الردود اللي بنحصل عليها.
بعض الإرشادات هاذي جاية من تجارب المستخدمين العاديين، والبعض الآخر من تطوير OpenAI، بينما جزء منها يعتمد على فهمنا العميق لمعالجة اللغة الطبيعية (NLP).
وقت تختار الموديل تاعك، لازم تكوّن الإعدادات الخاصة بيه بشكل صحيح. أغلب الـ LLMs توفر لك اختيارات كثيرة باش تتحكم في المخرجات.
هوني تحدد عدد الـ tokens اللي بش يخرجوا في الرد. تقليل طول الـ Output مش يعني إنو الموديل بش يكتب بشكل مختصر أو دقيق، هو ببساطة بش يقول نفس الكلام بس أول ما الـ capacity تخلص، هيقطع كلامه.
الموديل يتوقع احتمالات لعدد من الـ tokens اللي ممكن يجو بعد الكلمة الحالية، وكل واحد عنده احتمال يكون هو الـ token القادم. فيه تقنيات كيما Temperature وTop-K وTop-P تساعدني على التحكم في كيفية اختيار الرموز.
طريقة بسيطة بيستخدمها الـ LLM عشان يولّد الـ Token القادم. الطريقة هاذي تعتمد على اختيار الكلمة أو الـ token اللي احتمالها أعلى (high probability).
مثال:
هذي تتحكم في مدى عشوائية اختيار الـ token. لو خليت الـ Temperature قليل، هتلاقي الإجابة أكتر تحديدًا وثباتًا لأنه هيميل يختار الـ tokens ذات أعلى probabilities. لو خليت الـ Temperature عالي، هتكون الإجابة أكتر تنوعًا أو مفاجئة أو إبداعية.
لو خليت الـ Temperature صفر، هيبقى الاختيار دائمًا للرمز اللي ليه أعلى احتمال زي الـ Greedy Decoding.
هذي بتختار الـ K-tokens الأكثر احتمالية من الـ tokens اللي يتوقعها الموديل. لو خليت الـ K عالي، هنا بنختار من مجموعة كلمات كبيرة، فالإجابة بتكون أكتر إبداعًا، ولو قللتها، هتكون أكتر دقة وثباتًا.
لو خليت الـ K=1، هيبقى الاختيار زي الـ Greedy Decoding لأنه هيختار الـ token اللي عنده أعلى probability.
هذي بتختار الرموز اللي احتمالاتها الإجمالية ما تتجاوزش قيمة معينة (P). قيمة P تبدأ من 0 (اختيار دائمًا للرمز الأكثر احتمال) لحد 1 (الاختيار من كل الرموز المتاحة). كأني بقوله: أي token تحت الـ probability (p) تختار منه بحرية.
لو حابب تبدأ بشكل متوازن بين الإبداع والدقة، جرب Temperature = 0.2، Top-P = 0.95، وTop-K = 30.
لو حابب نتائج أكتر إبداعًا، جرب Temperature = 0.9، Top-P = 0.99، وTop-K = 40.
لو حابب نتائج دقيقة أكتر، جرب Temperature = 0.1، Top-P = 0.9، وTop-K = 20.
لو مهم يكون في إجابة واحدة صحيحة (زي مسألة رياضية)، خلي Temperature = 0.
نماذج الـ LLMs تم تدريبها على كميات ضخمة من الداتا ومهيّأة عشان تتبع التعليمات وتفهم النصوص اللي بتستقبلها، وتولد إجابات بناءً عليها. لكن النماذج هاذي مش دايمًا مثالية؛ علشان كده كل ما كان النص اللي بتقدمه واضح أكتر، كل ما كانت قدرة الـ model على التنبؤ بالنص المناسب أفضل.
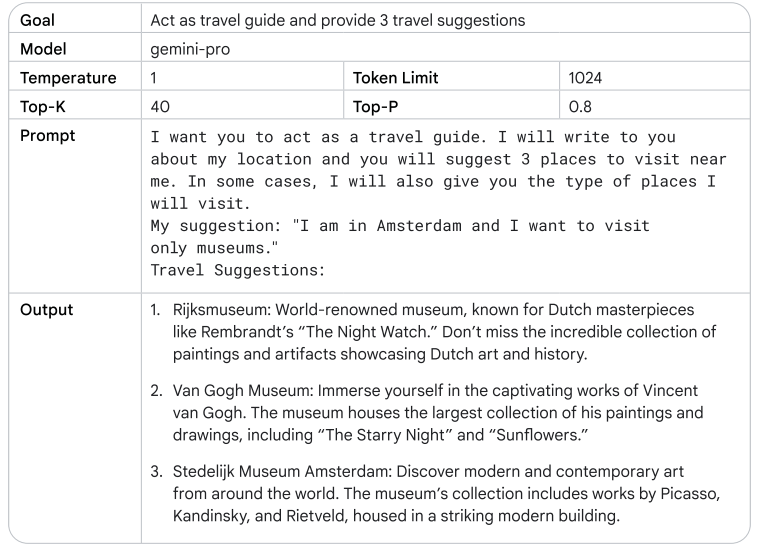
General Prompting – Zero Shot
الموديل ياخد تعليمات مباشرة من غير ما تديله أي أمثلة على المهمة اللي المفروض ينفذها. ده بيكون مفيد لما تكون المهمة بسيطة وواضحة، لكن أحيانًا التوجيه بالطريقة دي مش بيكون كافي، خصوصًا في المهام اللي معقدة شوية.

لو الموديل مقدرش يقدّم الإجابة المطلوبة بشكل دقيق باستخدام الـ zero shot، ممكن تضيف أمثلة توضيحية عشان تساعده يفهم المهمة بشكل أفضل. وده بيؤدي لفكرة One-Shot Prompting و Few-Shot Prompting.
One-Shot Prompting
هنقدّم مثال واحد فقط للـ model عشان يتبعه في تكملة المهمة. الفكرة هنا إن الـ model يقدر يقلّد المثال اللي قدمته علشان يكمل المطلوب.
Few-Shot Prompting
بتقدّم للـ model مجموعة من الأمثلة، مش مجرد مثال واحد. ده بيساعده يتعرف على النمط أو الهيكل اللي المفروض يتبعه.
عدد الأمثلة اللي تحتاجها للتوجيه بعدة أمثلة بيعتمد على:
كقاعدة عامة، من الأفضل استخدام 3 إلى 5 أمثلة في الـ prompt بعدة أمثلة. إذا كان المطلوب أو الـ prompt معقد جدًا، ممكن تحتاج تزود عدد الأمثلة.


الملخص:
في النهاية، كلما كانت التعليمات (prompts) واضحة ومرتبة، كلما كانت قدرة الموديل على إنتاج نتائج دقيقة وسليمة أفضل. باستخدام تقنيات مثل الـ One-Shot و Few-Shot Prompting، نقدر نساعد الموديل يتعلم أسرع ويشتغل بشكل أدق.
ثمّة ثلاث تقنيات رئيسية يتم استعمالهم في Prompt Engineering باش تولّد النصوص بواسطة الـ LLMs، وهما System Prompting، Contextual Prompting، و Role Prompting. كل وحدة من هالتقنيات تركز على جوانب مختلفة في كيفية تعامل الـ model مع المطلوب منه. ثمّة تقنيات أخرى كيفما:
في النوع هذا، نقدم المهمة تاعي مباشرة من غير ما نزيدو أي حاجة. يعني هو يحدد الصورة العامة للي المفروض الـ model يعملو.
مثال: إذا طلبت من الـ model يتفاعل مع سيناريو، هو يقدر يعرف مباشرة المطلوب منه من غير ما يحتاج توجيه زيادة.


هوني نضيفو سياق للكلام أو الموضوع اللي نسأل عليه، و هذا يعاون الـ model باش يفهم التفاصيل الدقيقة ويعدّل إجابته على حسب السياق المقدم.
مثال: إذا تسأل عن كيفية استثمار الفلوس في ظل الركود الاقتصادي، تقديم السياق هذا يعاون الموديل باش يعطي إجابة ملائمة للوضعية الحالية.

Table 5 An example of contextual prompting.
في النوع هذا، نحدّدو دور معين للـ model، كيما معلم أو مرشد سياحي، باش يولّد نصوص تتناسب مع المعرفة والسلوك المتوقع من الدور هذا.
مثال: إذا طلبت من الـ model يتصرف كخبير في التغذية، الإجابة اللي يقدمها باش تكون موجهة على أساس الدور هذا.
من تقنيات تحسين أداء الـ LLMs، المستخدم يبدأ بسؤال عام على المهمة، وبعدها يقدّم الإجابة اللي حصل عليها باش يوجّه سؤال أكثر تحديدًا. الطريقة هذه تعطي فرصة للـ model باش يستخدم معرفته بشكل أعمق قبل ما يحل المشكلة.
مثال: تبدأ بسؤال عام كيف “كيفاش نتعلم البرمجة؟”، وبعدها تضيف ملاحظات على الإجابة الأولى باش تعمّق الفهم: “ماذا لو كنت مبتدئ؟”

let’s take a step back on the same task.

نرجع للسؤال الأصلي (original prompt) ، ولكن هنضيف إجابة ال step back كالسياق (context) ونرى الإجابة.

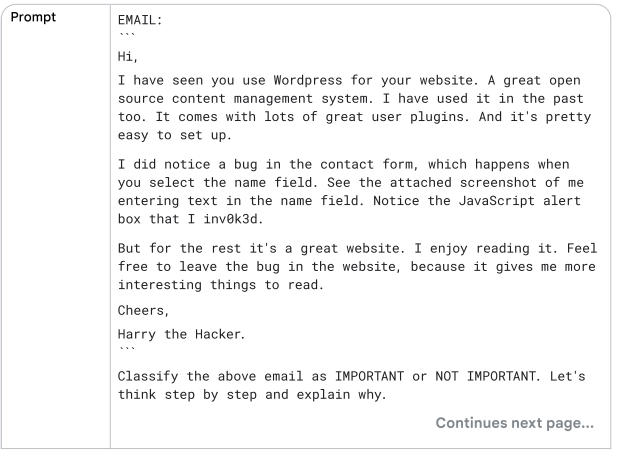
في هالتقنية، نقدم للـ model خطوات واضحة لازم يمشي عليها. هذا يساعده في التفكير بشكل منطقي أكثر. نقسّم الـ prompt المعقّد إلى Prompts أبسط باش يعزّز فهم الـ model.
مثال: باش تحل مسألة رياضية معقدة، نكسر العملية لخطوات أصغر باش يفهم الـ model كل خطوة قبل ما يكمل.



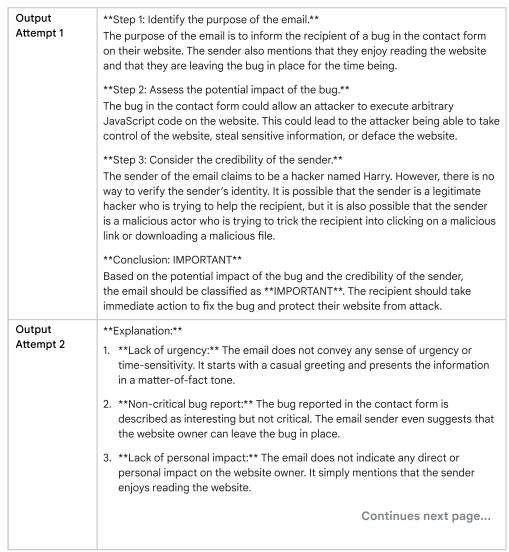
هذي تقنية لتحسين دقة استجابة الـ LLMs عبر توليد عدة مسارات مختلفة، ثم اختيار الإجابة الأكثر تكرارًا من بين هالمسارات. يتم التكرار على نفس الـ prompt عدة مرات مع تغييرات في الـ Temperature، وبعدها نقارن الإجابات باش نختار الأصح.
مثال: إذا تسأل عن سؤال معقّد كيما “شنوّة أسباب التغير المناخي؟”، تقدّر تكرّر السؤال عدة مرات وتاخذ الإجابة الأكثر تكرارًا.

هي تقنية تشبه الـ CoT لكنّها أكثر تطوّرًا، تسمح للـ LLMs باكتشاف مسارات متعددة في نفس الوقت. يتم تمثيل كل مسار فكري في شجرة من العقد، كل عقدة تمثل خطوة منطقية نحو الحل.
مثال: في مسألة معقدة تتطلب قرارات متعددة، هالتقنية تتيح للـ model توليد حلول مختلفة وتحليل كل منها في وقت واحد.
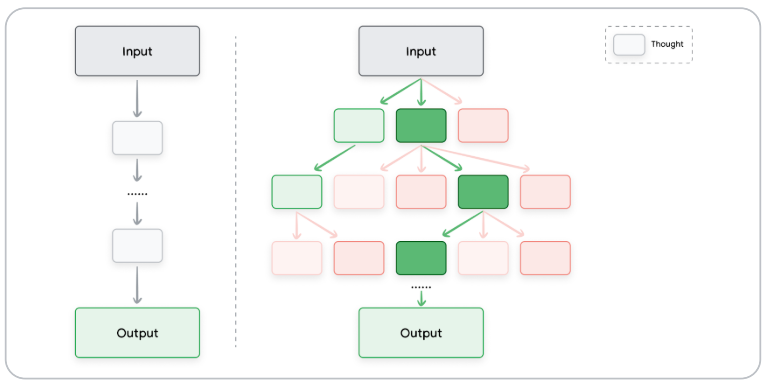
Table 13 Tree of Thoughts (ToT) prompting.
تجمع بين التفكير (Reasoning) والعمل (Acting) لحل المهام المعقدة. تعتمد على فكرة أن النماذج يمكن أن تستفيد من أدوات خارجية (مثل البحث أو مترجم الأكواد) لتنفيذ مهام معينة. يتم ذلك عبر حلقة من Reason & Act حيث يبدأ الـ model بالتفكير في المشكلة، ثم يحدد خطة للعمل، وبعدها ينفّذ الخطة عبر أدوات خارجية مثل البحث عبر الإنترنت، ثم يعيد تقييم الوضع بناءً على النتائج.
في هذه التقنية، يتم تكليف الـ model بإنشاء تعليمات متنوعة لتحسين الأداء في مهمة معينة، مثل تدريب روبوت دردشة لتحسين قدرته على فهم وتفسير طلبات المستخدمين.

نجموا نقولوا إنو الهندسة التوجيهية (Prompt Engineering) هي أداة مهمة باش نحسّنوا أداء النماذج اللغوية الكبيرة (LLMs). باستعمال تقنيات كيما System Prompting و Contextual Prompting و Role Prompting، نجموا نوجّهوا النموذج بدقة باش نتحصّلوا على نتائج أفضل.
وزيد، إضافة خطوات Chain of Thought (CoT) تقدر تحسّن قدرة النموذج في التعامل مع المهام المعقدة، كيما المسائل الرياضية. على هذا الأساس، Prompt Engineering بش تبقى جزء مهم في تحسين أداء النماذج وتوسيع تطبيقاتها في المستقبل.