

توا YouTube تخدم أكثر من 2 مليار مستخدم، والعدد الهائل هذا يتعامل يوميًا مع مئات الساعات من الفيديوهات اللي تتنزل كل دقيقة.
واللي يمكن يفاجئ برشة ناس هو إنهم يعتمدوا أساسًا على MySQL، قاعدة البيانات اللي أغلبنا استعملناها في مشاريعنا الصغيرة.
لكن السر ما هوش في MySQL بيدها، السر في الطريقة الذكية اللي استعملوها بيها باش يوسّعوها ويخلوها تخدم على نطاق عالمي.
في الأول، YouTube كانت تستعمل MySQL كقاعدة بيانات واحدة، تخزن فيها الكل: المستخدمين، الفيديوهات، التعليقات، وكل البيانات الأخرى.
لكن مع الوقت، ومع التزايد الكبير في عدد المستخدمين والـ Traffic، النظام بدا يتعب ويتبطأ، والـ Queries ولات ثقيلة برشة.
وهذا نفس السيناريو اللي يصير في أي Application يبدأ صغير وبعد يكبر:
في الأول قاعدة بيانات واحدة تكفي، أما كي تكبر الخدمة وتزيد الـ Load، تبدأ المشاكل، ونضطروا نلقاو حلول توسّع النظام بدون ما يطيح الأداء.
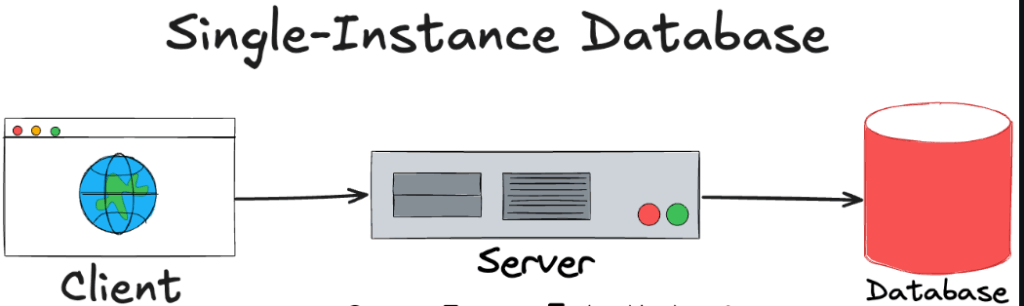
مع الحمل الكبير على قاعدة بيانات واحدة، صارت مشاكل كيما:
قدام كل المشاكل هاذي، YouTube قرروا ما يبدلوش MySQL، بل يطوروها ويعملوا فوقها حلول تخليها تتحمل الضغط العالمي.
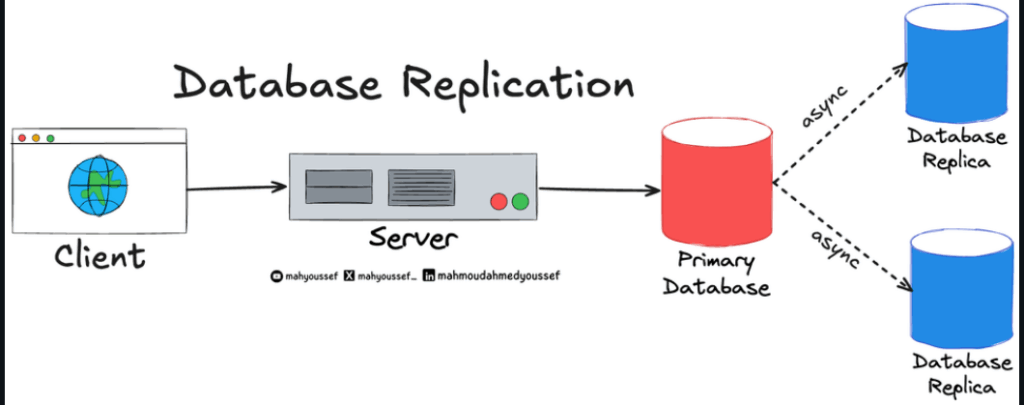
أول خطوة خذوها كانت MySQL Replication:
يعني يعملوا نسخة رئيسية (Primary) ونسخ ثانوية (Replicas) مخصصة للقراءة فقط.
وهكا يتحول النظام إلى MySQL Cluster:
فيه Node رئيسي وأكثر من Replica، يخدموا مع بعض ويتقاسموا الحمل.
لكن الـ Replication في MySQL وقتها كان Single-threaded، يعني نسخة وحدة تنفذ التحديثات وحدة بوحدة، وهذا يعمل تأخير في التزامن بين النسخ.
حسب CAP Theorem، يلزم تختار بين ثلاث خصائص:
Consistency، Availability، و Partition Tolerance — وما تنجمش تحقق الثلاثة في نفس الوقت.
YouTube فضلت Availability، يعني الخدمة لازم تبقى متوفرة حتى لو بعض البيانات مش محدثة في اللحظة.
البيانات تولي Eventually Consistent، تتحدّث مع الوقت.
لكن، في بعض الحالات، كانوا محتاجين Fresh Data فورًا.
فشنوّا عملوا؟
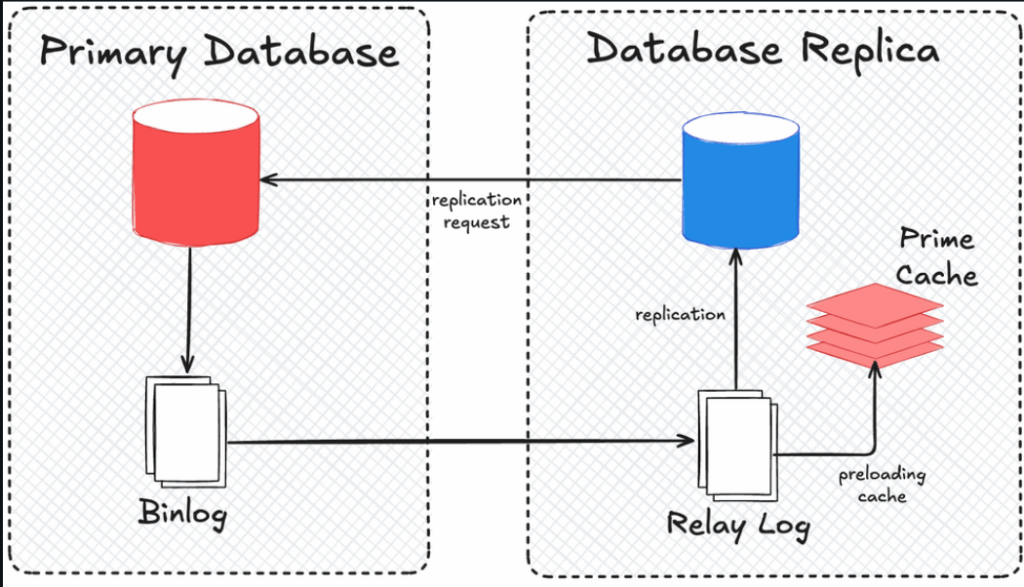
المشكل الثاني إنّ الـ Replication كان بطيء لأنّه يعتمد على الكتابة في الـ Disk.
باش يحلّوا المشكلة، YouTube قرروا يعملوا النظام In-Memory Bound باستعمال Cache.
يعني قبل ما الـ Replica تقرأ من الـ Disk،
تبدأ تقرأ من Cache اللي فيه نسخة مسبقة من الـ Binary Logs.
هكا الـ Replication ولا أسرع ببرشة، والـ Lag بين الـ Primary والـ Replicas تقريبًا اختفى.
الحل هذا خفّف الضغط على القرص (Disk) وخلّى النظام أكثر سرعة وثبات.
بعد كل هذا، البيانات ولات كبيرة برشة على Instance واحدة.
حتى مع الـ Replication والـ Cache، بقات الـ Bottleneck موجودة.
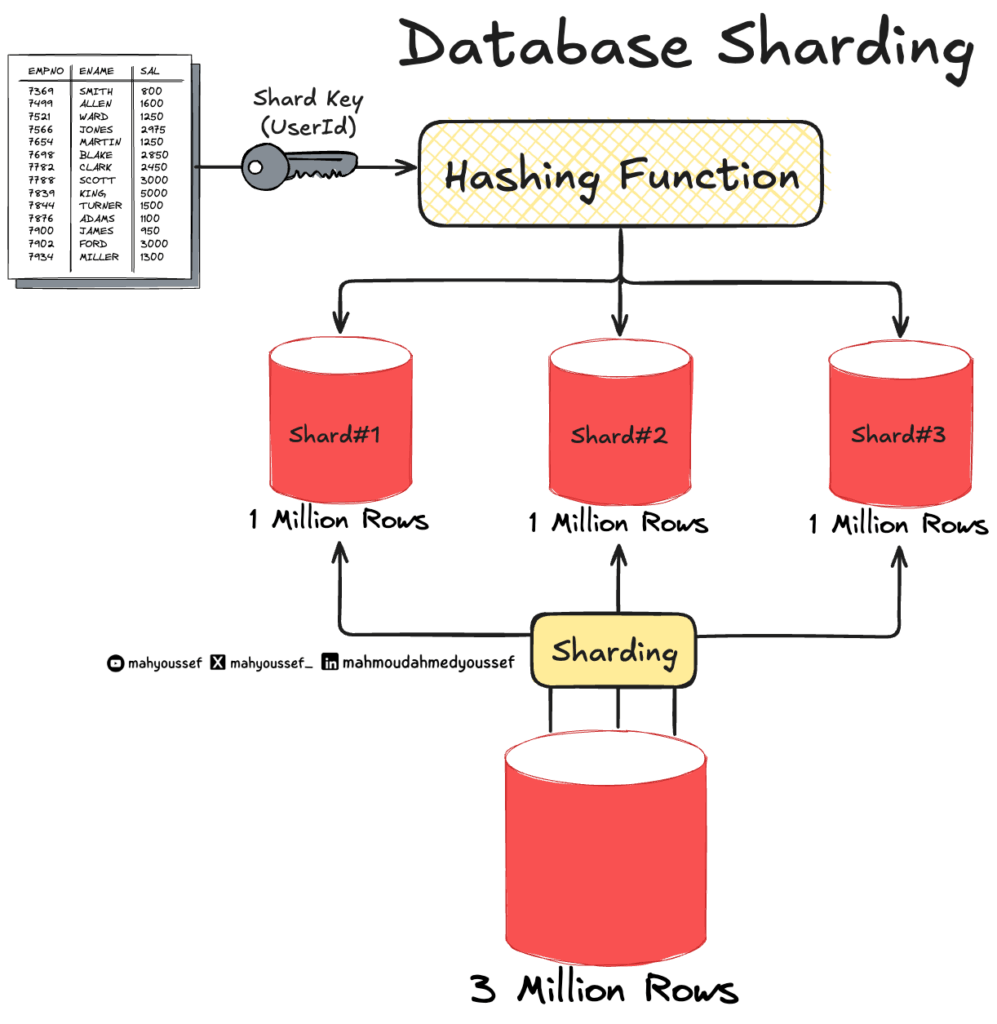
الحل كان Sharding: تقسيم البيانات على أكثر من قاعدة بيانات (Shards).
كل Shard فيه جزء من البيانات، مثلاً:
المستخدمين يتقسموا حسب الـ User ID، كل مجموعة في قاعدة خاصة.
لكن Sharding زاد النظام تعقيد:
التطبيق لازم يعرف أي Shard يحتوي البيانات المطلوبة ويبعثلها الـ Query بالضبط.
والـ Joins بين الـ Shards ولات صعيبة برشة ومكلفة في الأداء.
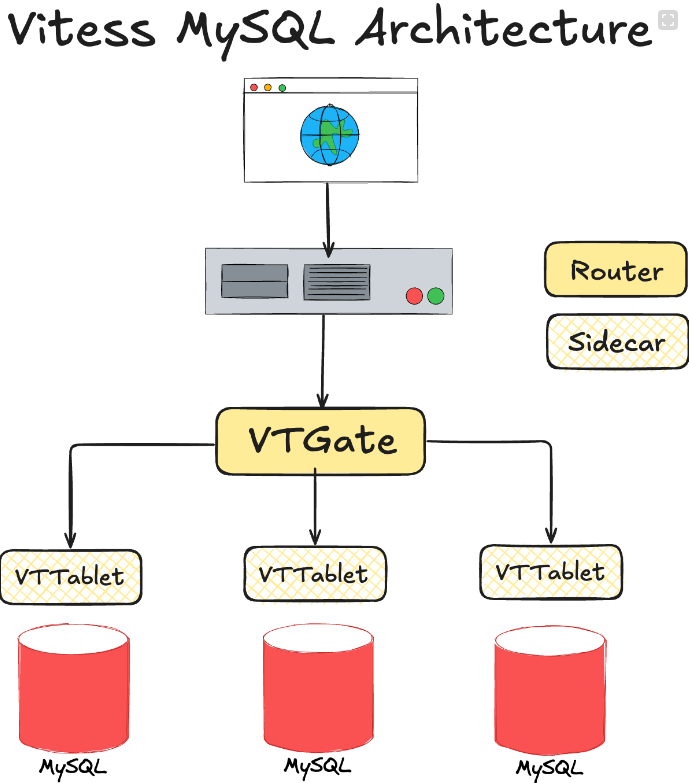
باش يتجاوزوا كل التعقيدات، YouTube بنات نظامها الخاص: Vitess.
وهو Open Source Layer فوق MySQL، يخلي النظام يتوسع بسهولة ويخدم كأنه قاعدة واحدة.
في Vitess فما زوز مكونات رئيسية:
النتيجة؟
التطبيق يشوف قاعدة بيانات واحدة، أما في الحقيقة فما عشرات الـ Shards و Replicas يخدموا في الخلفية.
وقت YouTube بدات تكبر وتخدم مليارات المستخدمين، واجهت تحديات كبيرة في:
MySQL وحدها ما كانتش كافية،
أما بالتطويرات الذكية — Replication, Caching, Sharding, وVitess —
ولّت YouTube تنجم تخدم 2 مليار مستخدم يوميًا من غير مشاكل.
YouTube ما بدلتش التقنية، بدلت طريقة التفكير.
ما هربوش من MySQL، بل طورّوها ووسّعوها باش تولي تخدم على مستوى عالمي.
وهذا دليل إنّ الإبداع مش دايمًا في التكنولوجيا الجديدة، بل في كيفاش نستعملوها بذكاء.
Alaeddine
أكتوبر 25, 2025Thanks
Great experience and information