

From Hallucination to Grounded AI: Deploying RAG in Banking
Banking is a domain where information accuracy, up-to-date data, and compliance are paramount. Yet traditional large language models (LLMs) on their own often struggle with these requirements – they only know what’s in their training data (which may be outdated) and can “hallucinate” confidently incorrect answers[1][2]. Retrieval-Augmented Generation (RAG) offers a solution by giving LLMs an external memory: the ability to fetch relevant facts from a knowledge repository on demand. Think of a standalone LLM as a talented employee with an amazing memory but no access to the company’s file servers, whereas a RAG-based system is like that employee with instant access to the company’s knowledge base and documents. The difference is profound – RAG enables answers that are both fluent and grounded in real data.
In simple terms, RAG is an approach that combines an LLM with a retrieval system. When a user asks a question, the system first retrieves documents (such as internal bank policies, product details, or regulatory texts) relevant to the query, and then the LLM generates an answer using not just its trained knowledge but also this retrieved information[3]. By including up-to-date, authoritative context in the prompt, RAG systems produce outputs that are more factual, relevant, and specific to the enterprise’s data[4]. In essence, the LLM “open-book consults” the bank’s own knowledge instead of relying purely on its memory.
This approach is particularly crucial in banking. Financial institutions possess vast troves of proprietary data – from procedure manuals and credit policies to customer communications – which generic models don’t have access to. If a banker questions an AI about a new internal compliance procedure or last quarter’s risk report, a vanilla model might give a generic or outdated answer. A RAG system, however, can pull in the bank’s proprietary data (documents, reports, emails, etc.), ensuring the answer reflects the latest facts and the bank’s unique context[5]. Moreover, grounding the LLM’s response in retrieved documents dramatically reduces hallucinations and increases accuracy, a critical benefit in a domain where incorrect information can lead to regulatory penalties or lost customer trust[5][6]. As a result, RAG has quickly become the default architecture for AI applications that require factual accuracy and domain-specific knowledge[7].
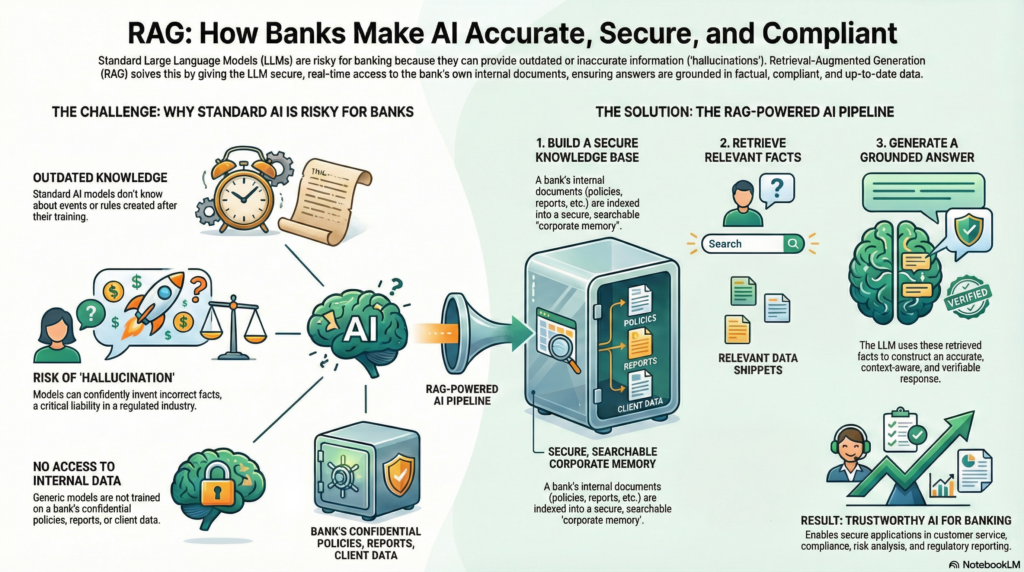
Retrieval-Augmented Generation is best understood as a pipeline that augments an LLM with a real-time information retrieval loop. Unlike a standalone LLM that generates answers from its training data alone, a RAG system connects the model to an external knowledge base. Whenever a query comes in, the RAG pipeline fetches relevant information from this knowledge source and feeds it into the model’s prompt. This ensures the model’s output is “grounded” in reality – it references actual documents or data rather than guesswork. In a sense, the model is taking an open-book exam: it has a “cheat sheet” of facts to refer to, which greatly improves reliability.
To illustrate the difference, consider a compliance officer asking about the latest AML (Anti-Money Laundering) regulation update. A regular LLM might produce a plausible-sounding summary based on what it saw in training (which could be outdated or not bank-specific). A RAG-based assistant, by contrast, would retrieve the exact text of the new regulation (e.g. from the bank’s compliance knowledge base or the official regulatory bulletin) and use that to craft its answer. The RAG answer will be precise, up-to-date, and likely include references to the source documents, allowing the officer to verify the details[8][9]. This ability to cite sources and provide a traceable trail of where information came from is a game-changer for trust and auditability in banking AI systems. Indeed, RAG “forces the assistant to provide a cited answer leading directly to the original source document,” as seen in real deployments at firms like Morgan Stanley[10].
Why does RAG matter? First, it addresses the knowledge cutoff problem – LLMs might not know about events or rules that emerged after their training data. RAG bridges that gap by retrieving current information on demand. Second, it injects domain-specific knowledge: public models are not trained on a bank’s internal manuals or client data for confidentiality reasons[11], but RAG can incorporate those private sources at query time without exposing them broadly. Third, RAG improves accuracy and reduces hallucinations by grounding the model’s output in real data. The model is far less likely to invent when it has concrete text to base its answer on[6]. And finally, RAG provides transparency and control – with source citations and controlled data access, users (and regulators) can trace exactly why the AI answered the way it did, which is essential in regulated sectors[9].
In summary, RAG is an approach that marries the generative strength of LLMs with the factual grounding of information retrieval[4]. It’s like giving the AI a tailored library for every question. For banks, this means AI assistants that actually “know” the bank’s latest policies, product details, and regulatory obligations, leading to responses that are both intelligent and compliant.
Implementing RAG in practice involves a pipeline of components that work together to fetch and incorporate relevant knowledge into LLM responses. Broadly, we can think of the RAG pipeline in two phases: an offline ingestion phase where the knowledge base is built, and an online query phase where retrieval and answer generation happen on the fly[12]. Below, we break down the main stages and components of a robust RAG system:
Example of a RAG system architecture. Documents are ingested and chunked into a vector database (with both dense and sparse indexes for hybrid search). At query time, the user’s question is embedded, relevant chunks are retrieved (and re-ranked) from the DB, and combined with the query as context for the LLM’s generation step. The result is a grounded answer, often with citations or references.
The first step is data ingestion – assembling the corpus of knowledge that the RAG system will draw upon. In a banking context, this likely includes an array of documents and data sources: policy documents, product brochures, procedural guides, financial reports, emails or support tickets, regulatory texts, knowledge-base articles, and more. These can come in different formats (PDFs, Word docs, HTML pages, databases, etc.), so ingestion involves loading and normalizing content from multiple sources[13].
Text extraction & cleaning: Raw documents often contain noise like headers, footers, navigation menus, or legal boilerplate (especially PDFs or web pages). A good ingestion pipeline will parse out the main content and clean it up[14]. This might mean removing irrelevant text (menus, ads), normalizing encodings and spacing, and converting documents into a consistent format (say, plain text or JSON). For example, if Bank XYZ is ingesting a set of regulatory PDFs, it would strip out repetitive footer text and just keep the core regulation text and section titles. Clean data not only improves embedding quality later but also ensures the retrieval isn’t distracted by junk content[14][15].
Metadata enrichment: Alongside content, it’s crucial to capture metadata for each document or section[16][17]. Metadata might include the document title, author, date of publication, document type (e.g. “Annual Report” vs “Email”), department or product category, and access permissions. In banking, additional metadata like confidentiality level or applicable region can be important. For instance, a chunk from a “Private Banking Policy – EU Region – Internal” document might carry tags like category: policy, region: EU, visibility: internal. Rich metadata allows the RAG system to later filter and rank results more intelligently (e.g. a query from a UK user might filter out region: US documents). It’s also used for access control, ensuring that documents are retrieved only for users with the right permissions (more on that in security)[18].
By the end of ingestion, we have a corpus of text (the bank’s knowledge) that is clean, segmented (if needed), and annotated with metadata. This sets the stage for the next critical step: chunking.
Chunking: Banking documents can be very large (think 100-page policy decks or lengthy compliance manuals). To make retrieval efficient and relevant, documents are split into smaller pieces called chunks. Each chunk might be a paragraph, a section, or a few hundred words long. Why chunk? Because searching and retrieving at a more granular level improves the chances of finding the precise piece of text that answers a query. If we indexed whole documents, a query about “late fees for mortgage loans” might return an entire 50-page policy, most of which is irrelevant, instead of the specific clause about late fees. Chunks serve as the atomic units of retrieval.
A naive way to chunk is to cut text every N tokens or characters (fixed-length chunking). A typical chunk size might be 300-500 tokens[19], but this can be tuned. Smaller chunks (e.g. 100-200 tokens) increase retrieval precision since each chunk is very focused[20]. However, very small chunks may lack context when the LLM tries to use them to answer a question (the model might see only a snippet in isolation)[21]. On the other hand, large chunks (say 1000+ tokens) carry more context for the model’s understanding but could dilute retrieval accuracy or hit limits on how many can fit into the prompt[20]. Choosing the right chunk size is a balancing act – RAG builders often start with a few hundred tokens per chunk as a compromise and adjust based on retrieval performance.
Semantic and hierarchical chunking: Instead of purely fixed-length splitting, advanced strategies look at the document’s structure and semantics. For example, semantic chunking uses meaning-based breaks – it might keep sentences together if they form a complete thought, or split when there’s a topic shift[22]. Hierarchical chunking preserves the outline of documents by chunking at logical boundaries (sections, sub-sections) and sometimes creating parent-child links. In practice, one might first split by top-level sections (e.g. each major section of a report) and then further split those sections if they are too large. This way, each chunk “knows” which section and document it came from. Preserving hierarchy through metadata (like storing the section title or parent heading alongside the chunk) is extremely useful – it provides context if needed and helps avoid losing the forest for the trees[23]. In Bank XYZ’s RAG system, for instance, each chunk from a policy manual could carry metadata of its section path (e.g. Document: Credit Policy, Section: Loan Origination, Subsection: Late Fees). That way, if multiple chunks from the same section are retrieved, the system or the user can see they’re related.
Overlap: Another best practice is allowing some overlap between chunks[24]. This means the end of chunk A might repeat a sentence or two at the start of chunk B. A 10-15% overlap (e.g. 50 tokens overlap on a 500-token chunk) is common[24]. The reason is to ensure context isn’t lost due to an arbitrary split. If an important sentence straddles a boundary, overlap helps keep the idea intact in at least one of the chunks. It slightly increases redundancy in storage, but greatly aids continuity.
Once documents are chunked, the next sub-step is embedding. Each chunk of text is converted into a numerical representation (a vector) via an embedding model[25]. Typically, this is a pre-trained model (like a BERT-based sentence transformer or other language model) that maps text to a high-dimensional vector space such that semantically similar texts end up near each other in that space. For example, a chunk describing “mortgage late fee policy” and another chunk about “penalties for late loan payments” would ideally have vectors that are close, reflecting their related content. Embeddings capture the gist or meaning of text beyond exact keyword matches[25].
It’s worth noting that choosing the embedding model can significantly impact RAG performance. Models vary in dimension (e.g. 384-d, 768-d), training data, and domain focus. Some banks use general-purpose models, while others experiment with fine-tuned embeddings for financial text. The goal is an embedding that can distinguish nuances in banking language – e.g., that “KYC requirements” and “customer due diligence” are related compliance terms. High-quality embeddings are especially crucial in compliance settings where terminology is complex and precision is critical[26][27].
At the end of this stage, we have each chunk represented as a vector, ready to be indexed for fast similarity search.
All those chunk embeddings now need to be stored in a way that we can quickly search and retrieve them by similarity. This is where the vector database (vector index) comes in[28][29]. A vector database is optimized to store high-dimensional vectors and perform rapid nearest-neighbor searches. When a query comes (also in vector form), it finds which stored vectors (chunks) are closest.
For RAG, you can use specialized vector DBs (like Pinecone, Weaviate, Vespa, Milvus, etc.) or add vector search capabilities to an existing database/search engine (PostgreSQL with pgVector, Elasticsearch/OpenSearch with dense vector fields, etc.)[30]. Many banks initially explore vector search by augmenting known platforms – for example, using an Elasticsearch cluster they already have, since it can handle both keyword and vector queries (more on hybrid search shortly). Others may prefer an in-house deployment of a dedicated vector DB for better performance at scale.
Indexing algorithm: Under the hood, vector DBs use approximate nearest neighbor (ANN) algorithms to make search efficient even with millions of vectors. A popular choice is HNSW (Hierarchical Navigable Small World graphs), which offers very fast recall with sub-linear scaling[31]. Another approach is IVF (inverted file index with clustering), which is more scalable for extremely large datasets but can be slightly less precise without tuning[32][33]. For practical purposes, a banking RAG deployment with, say, up to a few hundred thousand chunks can easily use HNSW for ~50ms search times. If you have tens of millions of chunks (imagine indexing all customer emails or transactions – big data), you might consider IVF or distributed indexing.
Metadata and filtering: Importantly, the vector database should also store the metadata for each chunk alongside the embedding. Many vector stores allow storing the raw text or an ID plus metadata fields. This enables filtered searches – e.g., you can query for nearest neighbors but only among chunks where document_type = “Policy” and region = “EU”, if a European regulation question is asked. This is vital in banking to narrow down results and enforce data segmentation. An example from our Bank XYZ: if an employee from Retail Banking asks a question, the system might restrict retrieval to chunks tagged with business_unit: retail (plus public info) to avoid accidentally pulling content from, say, the Corporate Banking or HR documents they shouldn’t see. Access control lists (ACLs) can be integrated at this layer by encoding permissions into metadata and applying filters at query time[34][18].
Storage and hosting considerations: Banks also weigh where to host the vector index. Some opt for on-premises or private cloud deployments for security, keeping all embeddings within their secure network. Others might use a cloud service with encryption and proper access control. The decision often involves balancing security vs. scalability. A local vector DB gives you full control (and might be required for sensitive data), while managed services can simplify operations for non-critical data. The key is that whatever solution is chosen, it should support encryption in transit and at rest, and ideally integrate with the bank’s identity management for access control on queries[35].
At this point, our pipeline’s offline part is done: we have a fully indexed vector database of all the important chunks from our documents, each with rich metadata and ready for retrieval.
With the system set up, we move to the real-time query phase. This is what happens when a user (say a bank employee or a customer via a chatbot) asks a question to the RAG-powered system.
Step 4.1: User query understanding and embedding. The user’s query (for example, “What is our latest refund policy for enterprise clients in Europe?”) first may go through an orchestration layer that interprets the request. This could involve checking the user’s identity and role, ensuring they are allowed to ask this question and see the potential answers (a security step), and then deciding which index to query. Once it passes these checks, the system converts the query from text into a vector embedding, using the same embedding model as was used for documents[36]. Consistency in the embedding model is important – the vector space of queries and documents must align. After this, the query is essentially a vector point in the same high-dimensional space as all those chunks.
Step 4.2: Similarity search in the vector DB. The query vector is then compared to the vectors in the database to find the nearest neighbors – i.e., the most semantically similar chunks of text[37][38]. The database returns the top K results (chunks) that scored closest by cosine similarity (or whatever distance metric is used). Here K is a tunable parameter: often 3–5 chunks are fetched for a very specific question, whereas a broader question might retrieve 10-20 chunks to cover more aspects[39]. In banking, you might use a slightly larger K if you expect answers to require piecing together multiple bits of info (for instance, a detailed credit risk question could draw from several sections of a risk report). However, retrieving too many chunks can introduce irrelevant information or exceed the model’s prompt length, so K is usually kept moderate.
One challenge with pure vector similarity is that it might miss exact matches for proper nouns, codes, or rare terms. For example, a policy ID code “PL-578” might not be semantically similar to anything else and could be missed if the embedding doesn’t capture it strongly. To address this, many RAG systems implement hybrid retrieval – combining semantic vector search with traditional keyword (BM25) search[40]. The idea is to catch those edge cases: exact phrases, numbers, names that a dense model might overlook. Hybrid search can be done by either maintaining a parallel keyword index or using a vector DB that supports a “sparse index” for keywords[41]. The results from both searches are merged (via rank fusion or other heuristics) to produce a better top-K list. By default, adopting hybrid retrieval in enterprise systems is wise because dense vectors excel at conceptual similarity, while sparse (keyword) search excels at precise token matching[41] – together covering each other’s blind spots.
Step 4.3: Filtering and re-ranking. Before finalizing the retrieved context, additional filtering and ranking steps often occur:
After these steps, we have a set of top-k retrieved chunks that are relevant, authorized, and sorted by relevance. Now it’s time to use them for answer generation.
Prompt construction (sometimes called “prompt injection”, not to be confused with the security term) is where we assemble the final query that will be sent to the LLM, which includes the retrieved context. Typically, the prompt is formatted as some combination of context + question + instructions.
For example, the system might construct a prompt like:
**Context:**
[Chunk 1 text]
[Chunk 2 text]
[Chunk 3 text]
**Question:** [Original user question]
**Answer:** (answer based on the provided context)
This format explicitly provides the model with the relevant information and asks it to base its answer on that context[45]. The retrieved chunks can be simply concatenated or sometimes lightly edited (e.g., extraneous sentences removed) to fit the prompt. It’s important to include any necessary citations or section references from the chunks, or at least ensure the model can identify which chunk content came from which source if we expect it to cite.
Prompt instructions: In addition to raw text, we often include an instruction in the prompt telling the model how to behave. For instance: “Using only the above context, answer the question. If the answer is not in the context, say you don’t know. Do not use any outside knowledge.” This kind of instruction helps keep the model “grounded” – it should rely on the provided info and not wander off into unsupported territory. We might also instruct it to quote or cite sources for transparency, e.g., “Provide the answer with references to the context excerpts by title or ID.” The exact phrasing of instructions is part of prompt engineering and can be refined to get the desired style of answer.
For a banking use case, additional prompt content might be included to enforce tone or compliance. For example, a customer-facing chatbot’s prompt might include a system message like: “You are a helpful banking assistant. Use a polite and professional tone. If regulatory or policy information is provided in the context, use it verbatim when possible.” This ensures the generated answer aligns with the bank’s communication standards.
Overall, prompt assembly is where the offline knowledge and the real-time question meet, setting up the LLM with everything it needs to generate a useful answer. Once the prompt is ready, it’s sent to the LLM for the final step.
Now the magic happens: Generation. The LLM (which could be a large model like GPT-4, or a smaller on-prem model depending on the bank’s choice) takes the prompt with embedded context and produces a response. Thanks to the retrieved grounding information, the model’s answer should directly leverage the content of those chunks, rather than relying on whatever was baked into its parameters[46]. This typically yields a more factually accurate answer that aligns with known documents. In our example, the model will likely draft an answer describing the refund policy for enterprise clients, quoting the specific terms if possible.
The benefits of this approach at generation time are clear: the model’s hallucinations are greatly reduced, because it doesn’t need to invent facts – it has them on hand[6]. The answers can include traceable references (like “according to the policy document updated in 2024, …”) which builds trust, especially if those references are shown to the user. The system can also handle up-to-date information – even if the model’s original training cutoff was a year ago, the presence of new context means the answer can reflect current reality (for instance, a regulatory change from last month)[6]. And importantly for banking, the model stays grounded in relevant data: it’s effectively constrained to talk about the content in the retrieved docs, which often prevents off-topic tangents and ensures compliance with what the bank knows to be true.
After the model generates the raw answer, many RAG systems include a post-processing step. This can involve:
Finally, the answer – now polished and vetted – is delivered to the user, often alongside citations or references to the source documents for transparency.
This completes the RAG flow: from the bank ingesting its data, to retrieving the right pieces for a question, to the LLM generating a grounded answer. Now, having covered the pipeline, we will look at some advanced techniques and practices that enhance RAG implementations, followed by how all this applies to specific banking use cases.
Implementing a RAG system involves many design choices. Here are some advanced strategies and best practices, particularly relevant to high-performing systems in a banking environment:
Now that we’ve covered how to build and optimize a RAG system, let’s focus on how these architectures are applied to concrete banking use cases and the specific considerations in those scenarios.
Retrieval-Augmented Generation can be applied across a wide range of banking functions. Below, we spotlight several key use cases – showing how RAG meets the needs of each and what to watch out for.
Scenario: A large bank (Bank XYZ) deploys an AI assistant to help both customers (via a chatbot) and call center employees (as an internal support tool) to answer questions. These questions range from “What’s the current interest rate on the Platinum Savings account?” to “How can I reset my online banking password?”. The answers exist in the bank’s knowledge base, FAQs, product brochures, and sometimes internal memos.
How RAG helps: The RAG system is fed with all relevant support documents: product details, fee schedules, IT helpdesk knowledge, policy statements, etc. When a question comes, the system retrieves the exact snippet – for example, the paragraph in the latest fee schedule about Platinum Savings interest rates – and the LLM uses it to answer with accuracy and context. This ensures the customer (or the service rep relaying the answer) gets an up-to-date and precise response.
For instance, Citibank has been reported to use an internal RAG-based assistant to help their customer support representatives in real time[58]. Instead of putting a caller on hold to manually search policy documents, the rep can query the AI assistant, which instantly retrieves the needed info (say, the section of the policy on mortgage prepayment charges) and provides a concise answer. This augments the rep’s capabilities, leading to faster and more consistent service.
Benefits: Customers get accurate answers faster, and front-line staff are empowered with a vast trove of institutional knowledge at their fingertips. RAG ensures that the answers are grounded in official policy, which reduces the risk of an agent improvising or giving a wrong answer. It also helps maintain consistency – every customer is told the same information (drawn from the single source of truth documentation). Moreover, because answers can be cited or linked to knowledge base articles, if a customer needs more detail, the agent or chatbot can easily provide it (e.g., “According to our Personal Loan Terms and Conditions (2024), the prepayment fee is 2% of the outstanding amount[10].”).
Key considerations: With customer-facing use, tone and style are important – the prompt should ensure the model’s answer is polite, clear, and compliant with marketing/branding guidelines. Also, privacy is crucial. If a customer asks about their specific account (“What’s my credit card reward balance?”), that may involve retrieving personal data. RAG can handle that by retrieving from a database or document specific to the user, but care must be taken to anonymize or secure sensitive details. One best practice is to have an anonymization layer – the system might retrieve raw data but only present what’s necessary, masking account numbers, etc., unless user-authenticated. In fact, experts advise that responses exclude or mask sensitive customer details, using techniques like entity replacement or not retrieving PII unless absolutely needed[59]. The system must authenticate the user’s identity and only retrieve their info, not anyone else’s. All these measures are to ensure compliance with privacy regulations and maintain customer trust.
Scenario: Banks must constantly generate reports for regulators and internal risk committees – from capital adequacy reports and MiFID compliance checklists to ESG (Environmental, Social, Governance) disclosures. These often involve pulling together information from various sources and explaining or summarizing it in light of regulatory rules. A RAG system can become a smart assistant for the Risk and Regulatory Reporting team.
How RAG helps: Consider a regulatory analyst at Bank XYZ who needs to prepare a summary of how the bank complies with a new Basel III provision. The analyst can ask the RAG system: “Explain how our bank meets the Basel III liquidity requirements as of Q4 2025.” The system will retrieve: (a) the text of the Basel III Liquidity Coverage Ratio (LCR) requirement from the regulatory documents, and (b) internal documents like the bank’s latest risk report or compliance memo that state current LCR figures and compliance status. The LLM can then generate a section of the report that says: “Basel III’s LCR requires banks to hold an adequate level of high-quality liquid assets to cover net cash outflows for 30 days[60]. As of Q4 2025, Bank XYZ’s LCR is 110%, exceeding the minimum 100% requirement, according to our internal Liquidity Risk Report[61]. This surplus is maintained by… [etc.]”. The beauty here is the model is weaving together the actual regulatory text with the bank’s actual data, ensuring correctness and completeness.
Another example is automating portions of regulatory reports. Banks like HSBC have used RAG-type approaches for tasks like Anti-Money Laundering investigations[60]. A system might retrieve relevant customer transaction data and known risk indicators to draft a Suspicious Activity Report (SAR) narrative for compliance officers. Instead of starting from scratch, the compliance officer gets a draft that is already filled with the pertinent details and references to policy – they just have to review and tweak it. In fact, RAG can ensure the SAR write-up cites the relevant regulations or internal controls that apply, which auditors love to see.
Benefits: Data grounding and auditability. For regulatory interactions, it’s vital to show where information came from. RAG naturally lends itself to that by citing source docs. If an auditor asks, “How did you come up with this statement?”, the team can point to the exact policy or data source that the RAG system pulled in[9]. It accelerates analysis by quickly assembling bits of relevant info (e.g., all references to “capital buffer” in recent documents) that an analyst might otherwise hunt for manually. It also reduces the chance of missing something critical, because the query can be run across the entire document corpus (maybe the system finds a mention of “LCR” in a meeting minutes file that the analyst might not have checked).
Key considerations: Accuracy and compliance are non-negotiable. The outputs will likely be reviewed by humans, but they must still be correct and complete. Thorough testing of the RAG system on past reporting tasks is needed to build confidence. Also, ensure the system’s context window can handle numeric data accurately – sometimes LLMs might mis-read a number from text, so critical figures might be better inserted via structured data retrieval (or at least double-checked).
Another consideration is change management: regulations update frequently, so the ingestion process must catch new regulatory texts (e.g., an update to MiFID II or a new guideline from the EBA) quickly. Keeping a “latest regulations” index and tagging documents by version date helps. The system should also be able to filter by date, like retrieving only the latest version of a rule[43] to avoid quoting superseded text.
Lastly, compliance reports often have a set format. Ensuring the generation step follows templates (perhaps via few-shot examples in the prompt of what a section should look like) can help the output slot into the final report with minimal editing.
Scenario: A credit risk officer or analyst is evaluating a corporate loan application or reviewing the credit portfolio. They might ask questions like, “Summarize the borrower’s risk profile and any policy exceptions noted” or “What are the main points from the last credit committee review of Client X?”. There are numerous documents: financial statements, internal credit memos, policy manuals (e.g., guidelines on lending limits, collateral requirements), and possibly news articles about the borrower.
How RAG helps: The RAG system can be the analyst’s research assistant. If asked to summarize Client X’s risk, it could retrieve the latest credit memo about Client X, the client’s financial ratios from a spreadsheet (if integrated or as text notes), and the relevant credit policy sections that apply (like if an exposure is above a threshold requiring special approval). The LLM then generates a concise risk profile: “Client X is a mid-sized manufacturing company with stable cash flows but high leverage (debt-to-equity 2.5 as of 2025)[62]. Our credit policy notes this leverage exceeds the typical threshold of 2.0 for this sector, but mitigants include a strong collateral package[62]. The last Credit Committee review (Jan 2025) flagged the dependency on a single supplier as a risk factor, though recent diversification has been observed (see Credit Memo Q4 2025).” This answer is drawing from multiple pieces: internal policy (threshold 2.0), internal data (leverage ratio), and internal analysis (committee notes). RAG makes it possible to fuse these sources in one answer.
Additionally, for portfolio-level analysis, an analyst might ask, “Which sectors are contributing most to our credit risk-weighted assets (RWA) and what’s the trend?” If the data is in reports, RAG could retrieve a summary of RWA by sector from an internal quarterly risk report and any commentary around it. While pure numbers might come from structured data, explanatory text (“the construction sector RWA increased due to new large exposures”) could be pulled from narrative sections and presented as answer.
Benefits: RAG gives analysts a quick way to gather insights without manually sifting through many PDFs and systems. It ensures they don’t overlook relevant information buried in a report or an email. Particularly, it can surface policy constraints or exceptions automatically – e.g., if a loan deviated from standard policy, the RAG might catch that mention in the approval document and highlight it. For underwriting new loans, an officer could query, “Any similar cases to this one in the past 5 years?” and RAG might retrieve past credit decisions that match the criteria (by vector similarity on description of the deal), effectively providing precedent cases. This is immensely useful for consistent decision-making.
Key considerations: A lot of the data in credit risk is sensitive (company financials, internal opinions, etc.), so access control is crucial. If RAG is used by various teams, ensure that, for example, Retail credit folks cannot accidentally retrieve corporate credit files, etc., via metadata restrictions[34]. Also, numeric info should be handled carefully – LLMs can sometimes mis-state figures if, say, the text says “$5 million” and the model misreads it. One trick is to keep critical numbers within the retrieved text short and maybe add them as part of the question to reinforce (e.g., “With debt-to-equity 2.5, what’s the profile…”). Alternatively, use structured data for numbers.
This use case might also involve integrating RAG with analytical tools: maybe the RAG system first gets some stats from a BI tool then explains them. Ensuring consistency between the numbers reported and the explanation is key (no hallucinating reasons that don’t exist!). A validation step by a human for final reports is still advised.
Finally, any recommendation or decision support provided by AI in credit risk will be scrutinized by regulators for fairness and bias. RAG can help explain the rationale (by pointing to actual risk factors in documents) which improves explainability compared to a black-box AI. Under emerging AI regulations, being able to audit the AI’s info sources is a plus.
Scenario: Compliance officers and investigators deal with tasks like monitoring transactions for AML, conducting KYC (Know Your Customer) checks, and keeping up with regulatory changes. They might ask the system: “List any transactions from last month that might violate policy X” or “Summarize any red flags in John Doe’s account history”, or “What changed in the latest update to EU AML guidelines?”. They rely on both internal data (transaction logs, client profiles, past case files) and external data (sanctions lists, regulatory directives).
How RAG helps: In AML transaction monitoring, a RAG-like system could combine a search of rules with transaction data. For example, if looking into John Doe’s account, the system retrieves relevant entries from his transaction history (perhaps as text like “$10k transfer to [Country], multiple in small amounts…”) along with excerpts from the AML policy that define suspicious patterns (e.g., structuring, high-risk jurisdictions). The LLM then produces a summary: “John Doe’s account shows patterns of structuring – 5 transfers just under \$10k each over two weeks to Country X, which is flagged as high-risk in our AML policy[60]. These transactions coincide with salary dates, which might indicate salary splitting to evade reporting thresholds. Further, one beneficiary appears in our internal watchlist (see Case #2019-5). Recommendation: escalate for detailed investigation.” This narrative is grounded in both data and policy. It saves the investigator from manually cross-referencing multiple systems and documents.
For KYC reviews, the system might retrieve the client’s onboarding documents, any negative news from a news database, and internal notes from previous reviews. The officer can get an automated “dossier” compiled by the AI, with key points highlighted (like “Passport verified, but address verification pending since last year; related accounts found with shared address…” etc.). This speeds up periodic reviews significantly.
Another angle is tracking regulatory changes. For example, the compliance department could query, “What are the key differences between EU AML Directive 5 and 6 relevant to our operations?” The system retrieves text from Directive 5 and 6, finds relevant sections (like changes in due diligence requirements), and summarizes the differences. It might say: “AMLD6 (2021) introduced explicit criminal liability for legal persons and expanded the list of predicate offenses, unlike AMLD5[63]. For Bank XYZ, the biggest change is the new requirement to conduct enhanced due diligence on cryptocurrency exchanges, which was not explicit in AMLD5. Our internal policy needs updating to reflect this expansion.” This is hugely valuable for compliance teams to quickly assess impacts of new rules.
Benefits: Efficiency and thoroughness. RAG can drastically cut down the time to compile information for a compliance case or regulatory analysis. It provides a safety net that all relevant info is considered because it can search across the entire corpus (whereas a human might forget to check one document or system). It also leaves an audit trail – each piece of info can be tied back to a source, which is reassuring if decisions are later questioned by regulators[9]. In fact, one of the powerful aspects of RAG in compliance is that it inherently creates a log of what sources were consulted for an answer, making the AI’s workings more transparent.
In terms of AML/KYC outcomes, a well-implemented RAG system can help catch compliance issues early (by correlating data points across systems) and reduce false negatives. It can also assist in drafting reports: some banks use AI to draft the narrative of suspicious activity reports (SARs) – RAG ensures those narratives reference the exact facts and regulatory clauses needed, which reduces revision cycles[8][9]. Petronella Technology Group’s playbook on secure RAG even notes that such transparency and consistency “makes the system understandable to regulators and improves … explainability”[9], which is crucial in this field.
Key considerations: The compliance use case probably handles the most sensitive data – personal customer information, potentially even allegations of wrongdoing. So the security model must be airtight: every query must be tied to a specific officer and purpose, and results should be filtered so an investigator only sees data for cases they work on (zero-trust approach)[34]. There should also be extensive logging (who queried what, and what results were returned) as compliance investigations often need audit trails and could become legal evidence.
Privacy is vital: even internally, strict controls on accessing customer data must be followed (aligning with GDPR principles). If the RAG system is used to process any personal data, ensure it’s allowed under the bank’s GDPR lawful basis and that data minimization is respected. For instance, if generating a summary for a SAR, maybe don’t pull the entire customer profile – just the relevant bits. Petronella’s guidance suggests using DLP (Data Loss Prevention) scanning in ingestion to detect PII or sensitive data and route it appropriately (perhaps to a more secure index or redact parts)[64]. Also, if any data is sent to an external LLM API, that’s a big red flag unless it’s anonymized or the provider is certified for such use – many banks choose on-prem or private cloud models to avoid this risk altogether.
Finally, there’s the matter of regulatory compliance for the AI itself. As regulations like the EU AI Act come into effect, a system used for, say, AML detection likely falls under high-risk AI use. That means the bank will need to ensure proper risk assessments, documentation, transparency, and human oversight. The RAG architecture helps here: it can log all decisions and provide the sources (supporting the Act’s logging and explainability requirements)[65]. But the bank will still have to validate the system (e.g., ensure it’s not biased, ensure it doesn’t systematically miss certain types of risks). Human analysts must remain in the loop, which is usually the case in compliance (the AI suggests, the human decides).
Building RAG systems in banking is not just about technical performance – it must be done in accordance with stringent security, privacy, and regulatory requirements. Here we outline some key considerations and best practices:
In summary, security and compliance need to be designed into every layer of the RAG architecture. Start with least-privilege access, encrypt everything, monitor usage, and have guardrails on inputs and outputs[73][74]. This defense in depth ensures that the powerful capabilities of RAG do not introduce new risks to the bank.
Retrieval-Augmented Generation is emerging as a cornerstone of AI strategy in the banking sector – and for good reason. It marries the strengths of large language models (fluid language understanding and generation) with the bank’s own trove of knowledge and data, yielding AI solutions that are accurate, domain-aware, and trustworthy. By grounding model outputs in real banking documents and data, RAG mitigates hallucinations and ensures that answers align with the latest policies, facts, and regulations[6]. For institutions like Bank XYZ, this means AI assistants can be safely deployed to enhance customer service, automate compliance checks, assist risk analysis, and more, all while keeping the AI on a tight factual leash.
Implementing RAG, however, is not a plug-and-play task – it requires thoughtful architecture and a multidisciplinary effort. We’ve seen how a RAG pipeline is built: from ingesting and chunking data, to indexing in a vector database, to hybrid retrieval and prompt assembly, culminating in an LLM-generated answer that’s backed by evidence. Each component must be calibrated to the bank’s needs – choosing the right chunking strategy, the right embedding model, the proper index type, and relevant safety filters. And beyond the technical layers, governance layers must ensure security (no unintended data leakage, strict ACL enforcement) and compliance (audit logs, bias checks, human oversight for critical decisions).
The examples in customer support, regulatory reporting, credit risk, and compliance illustrate that RAG isn’t a one-trick pony but a general paradigm adaptable to numerous banking scenarios. Early adopters in the industry (from Morgan Stanley’s advisor assistant to JPMorgan’s IndexGPT research tool) demonstrate tangible benefits – improved productivity, faster access to information, and more consistent outputs[75][76]. A Goldman Sachs internal report even noted significant productivity gains when developers used a RAG-augmented AI assistant[76], underscoring that the value goes beyond just customer-facing use – it’s also about empowering employees with knowledge at their fingertips.
For Bank XYZ or any financial institution considering RAG, here are a few closing recommendations:
In conclusion, Retrieval-Augmented Generation offers a blueprint for responsible, effective AI in banking. It recognizes that in this industry, knowledge is power, but only if used correctly. By linking AI to the bank’s knowledge while maintaining rigorous controls, RAG enables a new class of applications that were previously too risky with stand-alone AI. It’s a prime example of technology augmenting human capability – not replacing the experts and advisors in a bank, but equipping them with better tools. An IT manager can think of it as building a smart “information highway” between the organization’s collective knowledge and the AI that interacts with users or supports decisions. With careful construction and governance of that highway, the bank can drive faster and more safely into the future of AI-powered finance.
[1] [2] [4] [11] [55] [56] [57] Retrieval-Augmented Generation (RAG) | Pinecone
https://www.pinecone.io/learn/retrieval-augmented-generation
[3] [6] [7] [12] [13] [14] [15] [16] [17] [19] [20] [21] [22] [24] [32] [33] [36] [37] [38] [39] [40] [44] [45] [46] [53] RAG Pipeline Deep Dive: Ingestion, Chunking, Embedding, and Vector Search | by Derrick Ryan Giggs | Jan, 2026 | Medium
[5] [30] [31] [54] [65] [66] Programme Exécutif IT Stratégie et Implémentation de lIA Générative et Agentique chez ODDO BHF.pdf
[8] [9] [10] [75] [76] 5 high-ROI uses of RAG models in banking and fintech: By John Adam
https://www.finextra.com/blogposting/29032/5-high-roi-uses-of-rag-models-in-banking-and-fintech
[18] [23] [34] [35] [41] [42] [43] [47] [48] [51] [52] [64] [67] [68] [69] [70] [71] [73] [74] [77] The Secure Enterprise RAG Playbook: Architecture, Guardrails, and KPIs – Petronella Cybersecurity News
https://petronellatech.com/blog/the-secure-enterprise-rag-playbook-architecture-guardrails-and-kpis
[25] [26] [27] [28] [29] [49] [50] RAG in Detail — How it works ?. Banking compliance and regulatory… | by Aruna Pattam | Medium
https://arunapattam.medium.com/rag-in-detail-how-it-works-092bfff70d27
[58] [59] [60] [61] [62] [63] AI in Finance: The Promise and Risks of RAG
[72] EU AI Act: A New Regulatory Era for Banking AI Systems – Latinia
https://latinia.com/en/resources/the-eu-ai-act-is-now-in-force