In today’s fast-evolving tech landscape, where delivering high-quality software swiftly is key, the roles of DevOps, Site Reliability Engineering (SRE), and Platform Engineering often come up in discussions. While these practices share overlapping goals, each has a distinct focus. Understanding their differences is crucial for businesses looking to streamline operations, improve system reliability, and accelerate innovation.
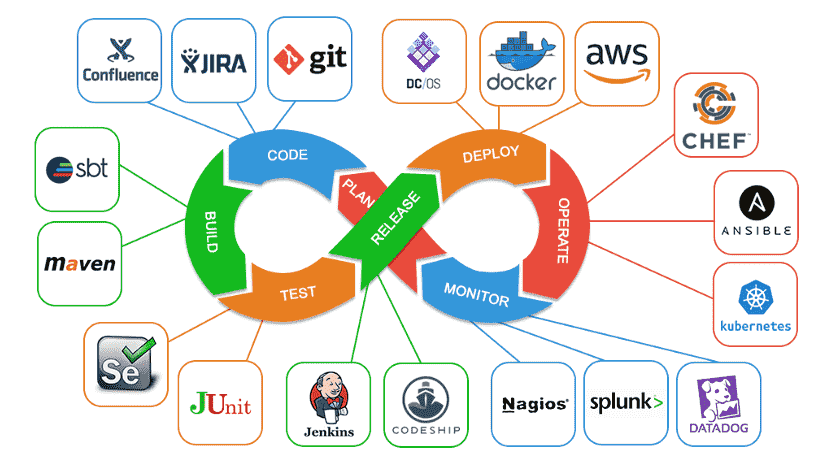
DevOps is a cultural and technical movement that bridges the gap between software development (Dev) and IT operations (Ops). Its primary goal is to reduce the friction between teams, fostering collaboration to deliver software more quickly and efficiently. By implementing automation, continuous integration/continuous delivery (CI/CD), and monitoring, DevOps enables frequent, high-quality software releases.
Collaboration: Developers and operations teams work together throughout the software lifecycle.
Automation: Automating repetitive tasks, such as testing and deployments, to ensure speed and accuracy.
Continuous Feedback: Monitoring and gathering data from production systems for faster issue resolution and improvements.
Agility: Enabling teams to react and adapt to changes quickly, reducing time to market.
DevOps aims to break down silos and create a seamless loop where development, testing, and operations are integrated into a continuous flow, ensuring that code changes can move from development to production swiftly with minimal disruptions.
Site Reliability Engineering (SRE) is a practice that evolved at Google and focuses specifically on ensuring the reliability, performance, and availability of software systems. It combines software engineering and systems administration skills, emphasizing automation to manage operations at scale. SREs treat operations as a software problem to be solved with engineering practices.
Key Responsibilities of SRE:
Service Level Objectives (SLOs): SREs define acceptable levels of system performance and uptime based on business needs.
Incident Response: When systems fail, SREs are responsible for quickly diagnosing and resolving incidents.
Error Budgets: SRE teams work with developers to strike a balance between innovation (deploying new features) and stability (system reliability), often using error budgets to gauge how much unreliability is tolerable before corrective actions are needed.
Automation: Like DevOps, SRE emphasizes automating tasks, but with a stronger focus on ensuring system stability and preventing downtime.
While DevOps focuses more on the process of development and deployment, SRE brings engineering rigor to the operational aspect of running large-scale, distributed systems, ensuring they stay reliable even under stress.
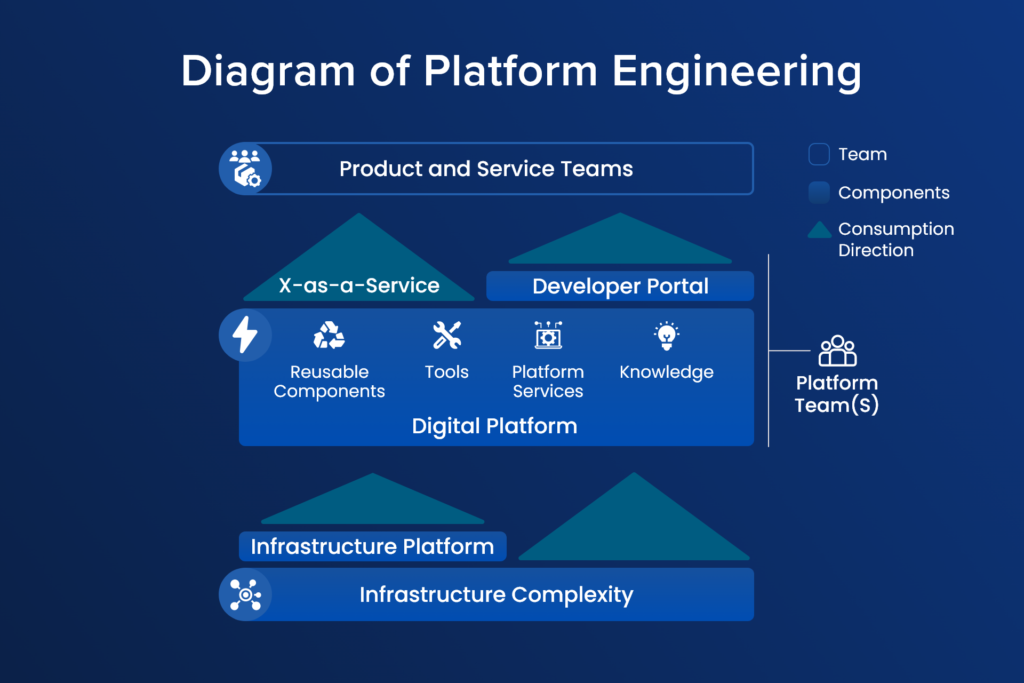
Platform Engineering is an emerging discipline that focuses on building internal platforms to support development teams by providing the tools, services, and infrastructure needed for product development. A platform engineer designs and maintains these systems, abstracting the complexities of infrastructure management so developers can focus on building applications.
Key Features of Platform Engineering:
Internal Developer Platforms (IDPs): Platform engineering creates reusable, self-service platforms that handle common tasks like provisioning environments, managing CI/CD pipelines, and monitoring services.
Abstraction of Complexity: Platform engineers aim to simplify the interaction between developers and infrastructure by abstracting complex tasks like networking, scaling, and security.
Efficiency: By standardizing infrastructure and tools, platform engineers help reduce duplication of efforts across teams, making the development process faster and more efficient.
Developer Experience: Platform engineering focuses on enhancing the developer experience, making it easier and faster to build, test, and release applications.
Unlike DevOps and SRE, which focus on the overall culture of collaboration and system reliability, platform engineering zeroes in on creating an internal ecosystem that empowers developers to be more productive without worrying about the underlying infrastructure.
Key Differences at a Glance:
Aspect
DevOps
SRE
Platform Engineering
Focus
Collaboration between development and operations.
Reliability, scalability, and system performance.
Building internal platforms for developer use.
Automation
Emphasizes automation throughout the software lifecycle.
Focuses on automating reliability tasks.
Automates infrastructure provisioning and management.
Managing operations using software engineering principles.
Providing developers with self-service infrastructure.
Team Dynamics
Developers and Ops collaborate, often as shared teams.
Separate SRE teams working closely with developers.
Platform team builds and manages internal tools for development teams.
Error Management
Focus on quick fixes and improvements.
Emphasizes “error budgets” to balance stability and innovation.
Ensures infrastructure reliability for developers but isn’t focused on fixing production issues.
How Do They Work Together?
DevOps, SRE, and platform engineering are not mutually exclusive. In fact, they can complement each other within a modern software organization:
DevOps creates a culture where development and operations collaborate seamlessly, speeding up the software delivery process.
SRE ensures that the software systems being deployed remain reliable and scalable by bringing an engineering approach to operations.
Platform Engineering supports both by building internal platforms that empower development teams with the tools and infrastructure they need to innovate efficiently.
Each of these practices plays a role in improving software delivery and system reliability. By understanding how they differ and where they intersect, companies can better structure their teams to optimize for speed, reliability, and innovation, creating a robust ecosystem for long-term success.
Team Structures in DevOps, SRE, and Platform Engineering
While these practices share similar goals—like improving system performance, reliability, and delivery speed—the way organizations structure teams around DevOps, SRE, and Platform Engineering can vary based on company size, culture, and technical needs.
DevOps Team Structure
DevOps isn’t necessarily a distinct team but more of a cultural shift that spans across multiple teams within an organization. It encourages developers and operations staff to work closely together, often forming cross-functional teams that include developers, QA engineers, operations, and sometimes security personnel (often referred to as DevSecOps).
Cross-Functional Teams: In a DevOps organization, teams consist of members with different skill sets but aligned towards the common goal of delivering software efficiently. For example, a single product team might include developers, operations engineers, and QA specialists who share responsibility for both code creation and production environments.
Shared Ownership: A core principle in DevOps is that development teams are also responsible for running their code in production. This concept, often called “you build it, you run it,” encourages accountability and helps break down silos between development and operations.
Automation Specialists: In larger organizations, there are often roles dedicated to CI/CD automation, ensuring that the deployment pipelines are smooth and efficient. These specialists help implement tools and processes that streamline testing, integration, and delivery.
SRE Team Structure
Site Reliability Engineering teams are generally separate from traditional development teams. SREs act as a bridge between development and operations, but their primary focus is on ensuring that systems are reliable and scalable. This team often functions independently, working closely with development teams to maintain system health.
Dedicated SRE Teams: SRE teams are often distinct from development, but they frequently embed engineers within development teams to build reliability from the start of the software development lifecycle. These embedded engineers offer guidance on system architecture, suggest improvements for resilience, and monitor production systems.
Ops as Code: SREs treat infrastructure and operations tasks as software problems, using automation to solve repetitive issues. They write code to manage tasks like scaling systems, balancing loads, or auto-healing after failures.
On-call Rotation: SREs often take on the responsibility of on-call duties. In case of incidents, they respond first, diagnosing the problem and either fixing it or escalating it to the appropriate team. In doing so, they maintain error budgets—allowing some level of failure as long as it doesn’t breach agreed-upon thresholds, ensuring a balance between feature deployment and system stability.
Collaboration with Developers: While SREs have a distinct role in maintaining system health, they work closely with development teams to prevent issues before they happen. Their feedback loop helps developers design more reliable, fault-tolerant systems.
Platform Engineering Team Structure
Platform engineering is typically responsible for designing, maintaining, and supporting the internal platforms that developers use for their day-to-day tasks. This team is usually highly specialized, focusing on infrastructure and tooling that makes development easier without burdening developers with underlying complexity.
Centralized Platform Team: A central platform team usually consists of infrastructure engineers, cloud architects, and automation experts who build and manage a self-service platform. This platform provides standardized services like CI/CD pipelines, cloud provisioning, and monitoring, all abstracted away so developers don’t have to worry about managing it themselves.
Service-Oriented Platform Engineering: In some organizations, platform engineering is divided into smaller teams that build specific services. For example, one team may focus on creating and managing containerized environments (e.g., Kubernetes clusters), while another handles the company’s internal CI/CD pipeline. This structure allows platform teams to scale and meet specific development needs.
Developer-Centric Approach: Platform engineers work closely with developers to ensure that the platform is intuitive and meets their needs. Often, this includes offering self-service interfaces that allow development teams to spin up new environments or deploy code without the need for deep infrastructure knowledge.
Empowering Developers: By providing reusable components and standardizing infrastructure practices, platform engineers reduce operational overhead for developers. This means developers spend more time writing code and less time worrying about infrastructure concerns like scaling, provisioning, or deploying.
How Teams Interact in Different Structures
DevOps as a Broad Culture: In a DevOps culture, teams are typically less siloed, and there’s a shared responsibility for production systems. Developers, QA engineers, and operations teams might work together in pods or squads, focusing on delivering value quickly while maintaining high-quality standards.
SRE as Guardians of Reliability: SREs operate with a more specialized focus, often collaborating with multiple product teams across the organization. They ensure that as development teams push out new features, the system remains stable and reliable. In this model, SRE teams act as consultants to development teams, offering guidance on building resilient systems and stepping in to resolve incidents.
Platform Engineering as Internal Service Providers: Platform engineers play a role akin to internal service providers. They do not directly impact product features but enable development teams to do their work faster and more efficiently. Platform engineering is ideal for large organizations with many development teams, as it creates a layer of abstraction that allows developers to focus on shipping code rather than dealing with infrastructure.
Challenges in Team Collaboration
DevOps and Cross-Team Communication: One of the main challenges with DevOps is fostering a truly collaborative culture. Some companies struggle to implement it effectively due to lingering silos between development and operations, especially in organizations with ingrained separation between these functions.
SRE and Ownership: Since SRE teams are focused on reliability, tension can sometimes arise between them and development teams. Developers may prioritize new features, while SREs prioritize system stability. The use of error budgets helps balance these concerns but requires continuous negotiation and communication.
Platform Engineering and Standardization: Platform engineering teams may face challenges around standardization. Not all developers appreciate using standardized tools, and some teams may push for custom solutions that suit their specific needs. Balancing flexibility with standardization can be a delicate task.
Choosing the Right Structure for Your Organization
The best structure depends on your organization’s size, complexity, and culture. Smaller teams might blur the lines between DevOps, SRE, and platform engineering, while larger organizations tend to benefit from specialized roles. Ultimately, all three practices aim to reduce friction in software delivery, enhance system reliability, and empower teams to move faster with fewer roadblocks.
By combining these approaches in ways that best fit your organization, you can build a robust operational framework that accelerates development, ensures reliability, and creates a seamless experience for your engineering teams.
Team Structures in Fintech: DevOps, SRE, and Platform Engineering
In the fintech sector, technology powers mission-critical applications such as payment systems, online banking, and trading platforms. Ensuring that these systems are secure, reliable, and scalable is essential, especially since downtime or vulnerabilities can lead to severe financial and reputational losses. Here’s how teams are typically structured in fintech companies to leverage DevOps, SRE, and Platform Engineering.
DevOps in Fintech
In the fintech industry, DevOps helps accelerate software delivery while ensuring that applications meet strict regulatory requirements. DevOps teams in fintech organizations must address compliance, data security, and financial transaction integrity without sacrificing speed or innovation.
Cross-Functional DevOps Teams: In fintech, DevOps teams are often integrated with security experts, creating what is known as DevSecOps. This approach ensures that security is considered throughout the entire software development lifecycle (SDLC), from coding and testing to deployment and monitoring.
Compliance Automation: One of the biggest challenges in fintech is adhering to regulatory requirements (such as PCI DSS, GDPR, or SOX). DevOps in fintech focuses heavily on automating compliance checks. This includes embedding compliance testing into CI/CD pipelines, ensuring that each code deployment is audit-ready and meets industry standards.
Data Integrity and Transaction Reliability: Fintech applications process massive volumes of financial transactions, and even a small error can result in major issues. DevOps teams ensure that systems are automated, redundant, and monitored in real-time, enabling the swift resolution of errors that could impact the integrity of financial transactions.
Continuous Delivery with Security Gates: While DevOps advocates for frequent releases, fintech companies often require additional security gates in their deployment pipelines. These gates run automated security scans, vulnerability assessments, and compliance checks to ensure that new features or updates don’t introduce risks into live environments.
SRE in Fintech
In fintech, SRE plays a critical role in ensuring that systems maintain high availability and resilience, especially when dealing with the complexities of real-time transaction processing and the need for zero downtime.
SLOs and SLAs Tailored for Financial Systems: Fintech applications require stringent Service Level Objectives (SLOs) and Service Level Agreements (SLAs). An example would be a trading platform where even milliseconds of downtime could result in significant financial losses. SREs in fintech are responsible for defining these SLOs, which might include metrics like uptime, transaction speed, or latency.
Real-Time Incident Response: In a high-stakes fintech environment, outages or delays in processing can have catastrophic impacts. SREs in fintech often manage real-time incident response, using advanced monitoring and alerting systems to detect and resolve issues before they escalate. This proactive monitoring ensures that systems can handle sudden spikes in traffic or unusual activity, such as during market openings for trading systems.
Resilience Engineering: SRE teams in fintech focus on resilience engineering, ensuring that systems can self-heal and continue functioning even in the face of hardware failures, network outages, or security threats. Redundant systems, failover mechanisms, and chaos engineering techniques are often employed to test and strengthen system resilience.
Error Budgets and Regulatory Constraints: SREs balance innovation and stability using error budgets, but in fintech, error budgets tend to be far stricter than in other industries. Due to regulatory and financial risks, SREs need to be highly conservative with the amount of downtime or performance degradation that can be tolerated before corrective actions are taken.
Platform Engineering in Fintech
Platform engineering in fintech focuses on building a robust, secure, and scalable internal platform that supports rapid development while ensuring compliance with regulatory standards. This internal platform provides tools, services, and infrastructure that development teams can use to build and deploy applications faster without compromising on compliance or security.
Compliance-First Platforms: In fintech, platform engineers are responsible for building platforms that enforce security policies and compliance standards automatically. For instance, they may create infrastructure-as-code templates that automatically configure environments to meet PCI DSS requirements for handling credit card data, ensuring that every deployed environment is compliant by design.
Standardized Infrastructure for Scaling: Fintech companies often experience unpredictable usage patterns, such as market volatility affecting trading volumes. Platform engineers create scalable infrastructure that can automatically adjust to these shifts in demand, ensuring high availability and performance. By using container orchestration tools like Kubernetes, platform engineers ensure that applications can scale seamlessly, even under heavy loads.
Self-Service for Developers: A key role for platform engineers in fintech is building self-service platforms that empower developers to provision environments, deploy services, and monitor their applications without direct infrastructure management. This reduces friction, allowing developers to innovate faster while ensuring that the platform enforces security and compliance in the background.
Security by Design: Platform engineers ensure that security is embedded within the platform itself. For example, they might integrate identity and access management (IAM) policies, encryption services, and secure storage solutions into the platform to ensure that any application or service built on it adheres to strict security standards.
Specific Challenges in Fintech
Regulatory Compliance: One of the biggest hurdles in fintech is ensuring compliance with global regulations. Teams need to incorporate compliance checks into every stage of the development lifecycle. For example, SREs and platform engineers must ensure that all logs, transactions, and user data are stored securely and that audit trails are maintained for any changes made to the system.
Security and Fraud Prevention: Cybersecurity is a top priority for fintech companies. DevOps teams must implement continuous monitoring and integrate security tools into every phase of the SDLC. SREs focus on maintaining security best practices in production, while platform engineers ensure that the underlying infrastructure adheres to zero-trust principles, minimizing the risk of fraud or cyberattacks.
High Availability and Disaster Recovery: Given the critical nature of financial services, fintech applications must ensure 99.999% availability. SREs focus on creating robust disaster recovery plans and failover systems to minimize downtime, while platform engineers build highly available platforms that can withstand failures in cloud providers or data centers.
Real-World Example: Stripe
A company like Stripe, a fintech giant providing payment processing infrastructure, embodies how DevOps, SRE, and platform engineering work together:
DevOps: Stripe uses DevOps practices to enable continuous delivery, allowing them to push updates and new features frequently while maintaining the security and compliance required for processing millions of transactions daily.
SRE: Stripe’s SRE teams ensure that their payment processing systems remain highly available, even during massive spikes in traffic (e.g., during Black Friday sales). Their SLOs focus on transaction completion times and uptime, and they use chaos engineering to test the resilience of their systems.
Platform Engineering: Stripe’s platform engineers have built internal developer platforms that abstract away the complexity of managing global infrastructure. Developers can focus on building new features, while the platform ensures compliance with various global financial regulations and scales automatically to meet demand.
Fintech-Specific Considerations
In fintech, the intersection of DevOps, SRE, and platform engineering is crucial for delivering reliable, secure, and compliant financial services. By understanding the specific challenges of the fintech industry, teams can optimize their structures and workflows to ensure that they meet the high standards required in this space. Each role—whether focused on fast, secure deployments (DevOps), reliability (SRE), or building secure, scalable platforms (platform engineering)—plays an essential part in the overall success of fintech applications.
Tools Used by DevOps, SRE, and Platform Engineers in Fintech
Given the fast-paced and compliance-driven nature of fintech, the right tools help these teams maintain efficiency, security, and high availability. Each practice—DevOps, SRE, and Platform Engineering—relies on different sets of tools, although there’s some overlap in functionality.
DevOps Tools in Fintech
CI/CD Tools: Jenkins, CircleCI, GitLab CI
Purpose: These tools automate the continuous integration and continuous delivery (CI/CD) pipelines, enabling frequent and safe code deployments.
Usage in Fintech: In a fintech environment, CI/CD tools integrate security checks, such as static code analysis (e.g., SonarQube) and vulnerability scanning, ensuring that each deployment adheres to compliance standards. GitLab CI, for example, supports GitOps workflows, automating infrastructure deployment and management with version-controlled code.
Configuration Management: Ansible, Puppet, Chef
Purpose: These tools automate the provisioning and configuration of infrastructure.
Usage in Fintech: For fintech companies handling sensitive data, configuration management ensures that systems are deployed consistently across environments, meeting regulatory and security requirements. Ansible is particularly popular due to its agentless architecture, reducing the attack surface in production systems.
Containerization and Orchestration: Docker, Kubernetes
Purpose: Docker helps package applications in containers, while Kubernetes manages container orchestration, automating deployment, scaling, and operations.
Usage in Fintech: Containerization improves environment consistency across development and production, which is critical for maintaining compliance. Kubernetes ensures fintech apps can scale dynamically to handle spikes in transaction volumes, such as during trading peaks or high-demand periods like Black Friday.
Monitoring and Logging: Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana)
Purpose: These tools monitor infrastructure and applications, track performance metrics, and provide real-time logging.
Usage in Fintech: In fintech, monitoring tools ensure systems remain within regulatory and SLA-defined performance parameters. For instance, Prometheus tracks system metrics like transaction latency and error rates, while the ELK Stack is crucial for maintaining audit trails—required for compliance.
SRE Tools in Fintech
Incident Management: PagerDuty, Opsgenie
Purpose: These tools manage and coordinate incident response, alerting engineers to critical system failures.
Usage in Fintech: Given the high stakes in fintech, SRE teams must be able to respond to outages or performance degradation within minutes. PagerDuty integrates with monitoring systems to trigger real-time alerts when thresholds are breached, ensuring fast remediation to maintain uptime and meet SLAs.
Chaos Engineering: Gremlin, Chaos Monkey
Purpose: These tools deliberately inject failures into systems to test their resilience.
Usage in Fintech: With the requirement for high availability, fintech companies use chaos engineering tools like Gremlin to simulate failures (e.g., database outages or network partitions). This ensures that systems can handle failures gracefully without affecting critical financial transactions or customer-facing services.
Service Level Management: Datadog, New Relic
Purpose: These tools monitor application performance and ensure that Service Level Indicators (SLIs) meet agreed Service Level Objectives (SLOs).
Usage in Fintech: Datadog and New Relic help SREs track key metrics like response times, transaction errors, and uptime to ensure that fintech services (such as payment gateways or trading platforms) remain reliable. These tools provide real-time dashboards that allow teams to track performance against their SLAs with financial institutions or customers.
Error Budget Tracking: Blameless, SLO Tracker
Purpose: These tools track the consumption of error budgets, ensuring a balance between stability and innovation.
Usage in Fintech: Error budgets are stricter in fintech than in many other industries. Tools like Blameless allow SREs to track how much “downtime” has been tolerated before crossing the error budget threshold. This allows fintech teams to strategically plan feature rollouts without risking system stability.
Platform Engineering Tools in Fintech
Infrastructure as Code (IaC): Terraform, Pulumi
Purpose: These tools enable developers and platform engineers to manage infrastructure through code, ensuring repeatable and consistent environments.
Usage in Fintech: Using Terraform, platform engineers can build self-service infrastructure that automatically configures environments according to compliance requirements. For example, they can set up AWS environments with predefined encryption, backup, and auditing policies.
Cloud Provisioning: AWS CloudFormation, Google Cloud Deployment Manager
Purpose: These tools provide infrastructure and service provisioning in cloud environments.
Usage in Fintech: In fintech, cloud provisioning must account for regulatory compliance. Tools like AWS CloudFormation help automate the setup of secure cloud environments with the required safeguards for financial data. Cloud engineers can use predefined templates to ensure that each new service follows strict security protocols.
Purpose: IDPs provide a self-service portal for developers, allowing them to easily access infrastructure resources, deploy applications, and monitor services.
Usage in Fintech: Platform engineering teams use tools like Backstage to give developers a centralized platform where they can spin up development environments, run tests, and deploy services without direct intervention from infrastructure teams. This ensures that developers can move quickly while the platform itself enforces security, compliance, and performance standards.
Purpose: These tools manage sensitive information, such as API keys, database credentials, and encryption keys.
Usage in Fintech: Handling sensitive financial data requires airtight security. Vault is used to securely store and access credentials in fintech applications, while ensuring that developers can’t accidentally expose secrets in code or logs. AWS Secrets Manager automates the rotation of these secrets to further enhance security and meet compliance mandates.
Key Fintech-Specific Considerations for Tool Selection
Security and Compliance:
In fintech, tools must integrate with compliance frameworks like PCI DSS, GDPR, and SOX. For example, DevOps tools like Jenkins or GitLab CI integrate security scanners that check code against compliance rules. Meanwhile, platform engineers use tools like Terraform with prebuilt compliance modules, ensuring infrastructure adheres to legal requirements.
High Availability:
Fintech companies handle mission-critical services that cannot afford downtime. Tools like Kubernetes for orchestration, combined with Prometheus and Datadog for monitoring, ensure high availability by detecting and responding to potential issues before they affect users.
Auditability and Traceability:
Maintaining an audit trail is crucial in fintech for legal and compliance purposes. Logging tools like the ELK Stack are vital, capturing detailed logs of system operations, user actions, and code deployments. This allows for full traceability of any changes made to systems—key for both security and audits.
Scalability and Performance:
Tools that support horizontal scaling, like Kubernetes and Terraform, are particularly useful in fintech, where demand can spike unpredictably. SRE and platform engineering teams rely on auto-scaling features and tools that support performance optimization (e.g., New Relic) to ensure seamless operation during periods of high traffic.
Choosing the Right Tools for the Job
In the highly regulated fintech industry, choosing the right tools for DevOps, SRE, and Platform Engineering teams is critical. Tools need to not only enhance productivity but also ensure security, compliance, and scalability. While there is some overlap in the tools used by these teams, each has its unique focus—DevOps is more geared towards automating the software delivery pipeline, SRE focuses on reliability and incident management, and Platform Engineering builds the internal ecosystem that allows developers to innovate while adhering to strict compliance standards.
By leveraging the right combination of tools, fintech companies can ensure efficient delivery, high system reliability, and compliance with industry regulations—all while supporting the fast-paced innovation that the fintech industry demands.
1. PayPal: Scaling DevOps for Global Transactions
PayPal, one of the largest online payment systems in the world, handles millions of transactions daily across the globe. Their reliance on DevOps principles has been key to maintaining uptime, scaling their infrastructure, and ensuring security.
How PayPal Leverages DevOps:
Automation at Scale: PayPal uses CI/CD pipelines extensively, automating code deployments, infrastructure updates, and testing. Jenkins and GitLab CI are part of their DevOps toolkit, ensuring continuous delivery of new features while maintaining compliance.
Compliance-Integrated Pipelines: PayPal must comply with strict financial regulations like PCI DSS. Their pipelines are integrated with automated security scans, checking for vulnerabilities and ensuring compliance standards are met before code hits production.
Containerization and Microservices: PayPal has shifted its monolithic architecture to a microservices-based one using Kubernetes and Docker. This allows teams to independently deploy services, reducing dependencies and enabling faster innovation without impacting the larger system.
Success:
By integrating DevOps practices, PayPal has been able to support global payment infrastructure while cutting deployment times drastically, improving overall time-to-market, and maintaining 99.99% uptime despite handling vast amounts of real-time financial data.
2. Stripe: SRE for Global Payment Reliability
Stripe is another fintech giant known for its developer-friendly payment APIs. Stripe has successfully implemented Site Reliability Engineering (SRE) to manage the massive complexity of real-time payments, ensuring that their system is resilient, reliable, and secure.
How Stripe Uses SRE:
Service Level Objectives (SLOs): Stripe sets strict SLOs for performance and uptime, given the critical nature of payments. For instance, they set transaction completion time SLOs, ensuring that users can process payments in milliseconds, regardless of the load on the system.
Real-Time Monitoring and Incident Management: Stripe uses tools like Datadog and PagerDuty to ensure real-time monitoring of their global infrastructure. SRE teams are immediately alerted to any potential incidents, ensuring they can respond and resolve issues before they impact users.
Chaos Engineering: To ensure their systems can handle unpredictable failures, Stripe uses chaos engineering tools like Gremlin. These tools introduce deliberate failures (such as database crashes or network outages) to see how resilient their system is under stress. This has helped Stripe build fault-tolerant systems that can recover quickly without impacting transaction processing.
Success:
By implementing SRE, Stripe has maintained exceptional reliability, handling millions of payments daily without downtime. Their focus on resilience ensures that even during high-traffic periods, such as Black Friday, their systems perform efficiently, maintaining high uptime and availability.
3. Robinhood: Platform Engineering for Scalable Growth
Robinhood, the commission-free stock trading app, has experienced massive growth in recent years. They’ve leveraged Platform Engineering to build an internal ecosystem that allows their developers to innovate rapidly while maintaining a reliable, compliant, and scalable platform.
How Robinhood Implements Platform Engineering:
Internal Developer Platform: Robinhood built a comprehensive internal developer platform that provides self-service tools for their engineers to deploy, manage, and monitor services. By abstracting the complexities of cloud infrastructure (AWS in their case), developers can focus on shipping code, leaving infrastructure concerns to the platform team.
Infrastructure as Code: Using tools like Terraform and Pulumi, Robinhood has created a standardized way to deploy infrastructure securely. These tools enable developers to provision environments with the correct security settings (e.g., encryption, IAM policies) in a matter of minutes.
Automated Security and Compliance: Given the sensitive nature of trading and financial data, Robinhood’s platform team integrates security policies into their infrastructure. Tools like HashiCorp Vault are used to manage secrets and credentials securely, while automated compliance checks ensure every deployment meets regulatory requirements (e.g., FINRA and SEC).
Success:
Robinhood’s Platform Engineering approach has allowed them to scale rapidly while maintaining security and compliance. By offering self-service infrastructure to developers, they’ve increased productivity and reduced the time to market for new features like crypto trading and fractional shares.
4. Square: Combining DevOps and Platform Engineering for Innovative Payment Solutions
Square, known for its payment hardware and software solutions, has integrated DevOps and Platform Engineering to support its vast network of payment services. These practices help Square maintain reliable payment processing, even as their product portfolio and user base expand.
How Square Uses DevOps and Platform Engineering:
DevOps for Speed and Security: Square’s teams utilize CI/CD pipelines to push out new features and updates quickly. They’ve automated the deployment process with tools like Jenkins and GitLab CI, ensuring that every release is tested and meets security standards.
Containerization for Flexibility: Square’s microservices architecture relies on Docker and Kubernetes for container orchestration, making it easier for teams to deploy, manage, and scale services independently. This has allowed them to quickly launch new services like Square Capital and Cash App.
Platform Engineering for Developer Productivity: Square’s platform engineering team has built an internal developer platform that abstracts the complexity of AWS infrastructure. This platform provides a set of reusable tools and services that handle everything from database provisioning to monitoring and logging, allowing engineers to deploy new services without worrying about infrastructure details.
Success:
Square’s combination of DevOps and Platform Engineering has led to faster feature deployment and the ability to scale services like Square Cash and Square Point of Sale globally, all while ensuring security and reliability for their customers.
5. Nubank: SRE and Platform Engineering for LatAm’s Largest Digital Bank
Nubank, the largest independent digital bank in Latin America, has adopted SRE and Platform Engineering to support its explosive growth. With over 70 million customers, Nubank relies on these practices to ensure that its systems are always available, secure, and scalable.
How Nubank Uses SRE and Platform Engineering:
SRE for Reliability: Nubank’s SRE teams use tools like Prometheus for monitoring and PagerDuty for incident response. Their SREs ensure that the bank’s services, such as credit card transactions and account management, meet strict SLOs to ensure uptime and reliability, even during peak usage.
Platform Engineering for Scalability: Nubank has built an internal platform that provides self-service infrastructure, allowing developers to deploy services in a standardized way. They use Kubernetes for container orchestration, ensuring that services scale seamlessly to handle spikes in demand, such as during salary payments or Black Friday.
Security and Compliance by Default: Nubank’s platform engineering team has embedded security policies into their infrastructure, using Terraform and AWS Lambda to automate compliance with Brazil’s banking regulations and data protection laws.
Success:
Nubank’s adoption of SRE and Platform Engineering has allowed them to handle massive growth while maintaining system reliability and regulatory compliance. Their ability to scale quickly, along with their focus on customer experience, has positioned Nubank as a leader in the fintech space.
Lessons from Successful Fintech Companies
These fintech companies—PayPal, Stripe, Robinhood, Square, and Nubank—demonstrate the effectiveness of DevOps, SRE, and Platform Engineering when implemented correctly. By focusing on automation, scalability, security, and compliance, these companies have been able to innovate rapidly while maintaining high availability and reliability, critical factors in the fast-paced world of fintech.
Whether it’s enabling developers with self-service infrastructure, automating compliance checks, or ensuring systems are resilient to failures, these companies have successfully leveraged modern engineering practices to stay competitive in the fintech landscape.
DevOps Tools
DevOps focuses on automating the development and operations lifecycle, ensuring faster, more reliable delivery of applications.
Category
DevOps Tools
Purpose
CI/CD Pipelines
Jenkins, GitLab CI, CircleCI
Automates the building, testing, and deployment of code, enabling continuous integration and delivery.
Version Control
Git, Bitbucket
Manages code versioning and collaboration across development teams.
Containerization
Docker
Packages applications in lightweight containers, ensuring consistency across environments.
Container Orchestration
Kubernetes, Docker Swarm
Manages the deployment and scaling of containers automatically.
Configuration Management
Ansible, Puppet, Chef
Automates infrastructure provisioning and config management across environments.
Monitoring and Logging
Prometheus, ELK Stack
Provides real-time monitoring and logging to identify and resolve issues during deployment.
Security Tools
SonarQube, Aqua Security
Integrates security scanning into the DevOps pipeline, ensuring code is secure and compliant.
Unique DevOps Focus:
Automating code deployments and ensuring continuous integration with fast feedback loops.
Using containers and orchestration tools to ensure applications are delivered consistently across environments.
SRE Tools
Site Reliability Engineering (SRE) focuses on system reliability, availability, and performance, while ensuring services can handle high-traffic, real-time usage.
Category
SRE Tools
Purpose
Incident Management
PagerDuty, Opsgenie
Coordinates incident response, alerting engineers to critical failures.
Monitoring & Alerts
Datadog, New Relic, Grafana
Monitors application performance and sets alerts based on predefined SLOs/SLIs.
Chaos Engineering
Gremlin, Chaos Monkey
Simulates system failures to test the system’s resilience and recovery ability.
Service Level Management
Blameless, SLO Tracker
Tracks Service Level Objectives (SLOs) and error budgets to balance reliability with feature velocity.
Automation for Stability
Terraform, SaltStack
Automates repetitive operational tasks, ensuring system stability through code.
Error Tracking
Sentry, Rollbar
Identifies and reports application errors, helping SREs to prioritize fixes.
Unique SRE Focus:
Tools for managing incidents, monitoring SLOs, and tracking error budgets to balance system reliability with innovation.
Chaos engineering tools test the system’s ability to withstand failures.
Platform Engineering Tools
Platform Engineering focuses on building internal platforms that support developers by providing infrastructure and services in a self-service, scalable, and compliant manner.
Category
Platform Engineering Tools
Purpose
Infrastructure as Code (IaC)
Terraform, Pulumi, AWS CloudFormation
Defines and manages infrastructure through code, ensuring consistency and easy deployment.
Cloud Provisioning
Google Cloud Deployment Manager, AWS CloudFormation
Provides developers with a self-service platform for managing environments and services.
Secrets Management
HashiCorp Vault, AWS Secrets Manager
Manages sensitive information such as API keys and database credentials securely.
Containerization & Orchestration
Docker, Kubernetes
Enables developers to deploy services consistently while platform engineers manage scaling and load balancing.
Security & Compliance
AWS IAM, Prisma Cloud
Ensures that infrastructure is secure and compliant with regulatory standards.
Unique Platform Engineering Focus:
Tools to create a developer-friendly platform that simplifies infrastructure management, while enforcing security and compliance policies.
Self-service tools allow developers to easily access infrastructure resources without deep operational involvement.
Tool Comparison at a Glance:
Tool Category
DevOps
SRE
Platform Engineering
CI/CD
Jenkins, GitLab CI, CircleCI
Not a primary focus
Integrates CI/CD tools into the internal platform
Incident Management
Slack, Jira for coordination
PagerDuty, Opsgenie
Rarely involved in direct incident response
Monitoring
Prometheus, ELK Stack
Datadog, New Relic, Grafana
Prometheus, Grafana used for platform monitoring
Containerization
Docker, Kubernetes
Kubernetes for system scalability
Kubernetes for managing developer environments
Infrastructure as Code
Ansible, Puppet, Chef
Terraform for automating reliability practices
Terraform, Pulumi, CloudFormation for scaling
Service Level Mgmt
Not usually a focus
SLO Tracker, Blameless
Managed within the platform for SLIs
Chaos Engineering
Not a primary focus
Gremlin, Chaos Monkey
Not a common practice
Secrets Management
SonarQube, Aqua Security (integrated into pipelines)
Integrated into operations for security
HashiCorp Vault, AWS Secrets Manager
Summary of Differences:
DevOps:
Emphasizes tools for automation, integration, and deployment pipelines.
Focuses on tools for containerization, version control, and collaboration.
SRE:
Relies heavily on monitoring, alerting, and incident management tools.
Includes tools for error budgets and chaos engineering to test system resilience.
Platform Engineering:
Uses IaC tools for managing infrastructure through code.
Focuses on building internal developer platforms that simplify infrastructure management, with a strong emphasis on security and compliance.
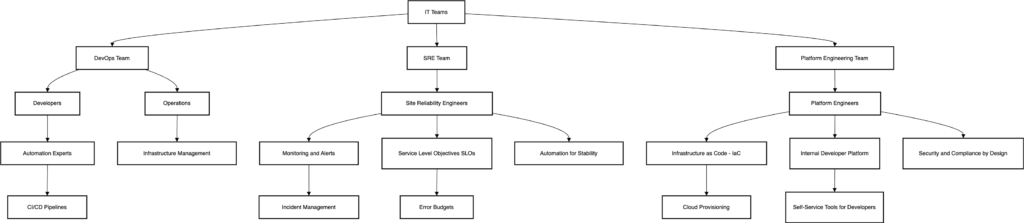
Target Operating Model (TOM) for a Company with IT-DEVS and IT-OPS Teams Organized Around SRE, DevOps, and Platform Engineering
A Target Operating Model (TOM) defines how a company organizes its teams, workflows, and tools to achieve its strategic objectives. For an IT organization structured around SRE, DevOps, and Platform Engineering, the goal is to balance rapid software delivery, system reliability, and scalable infrastructure management, all while maintaining security and compliance.
Below is a detailed TOM for a mid- to large-sized company with IT Development (IT-DEVS) and IT Operations (IT-OPS) teams using these three key approaches.
Organizational Structure Overview
High-Level Team Structure
IT-DEVS: Responsible for feature development, codebase management, and testing.
DevOps teams within IT-DEVS work on bridging development and operational processes, focusing on automation, continuous integration/continuous delivery (CI/CD), and collaboration.
IT-OPS: Manages infrastructure, system reliability, incident response, and platform availability.
This includes SRE teams that focus on service reliability and performance.
Platform Engineering teams manage the internal platform used by developers, ensuring that infrastructure is scalable, secure, and compliant.
Key Roles and Responsibilities
A. DevOps Team
Primary Focus: Ensure smooth, automated delivery pipelines, bridging the gap between IT-DEVS and IT-OPS.
Team Composition:
Developers: Write code, build features, and participate in deploying and monitoring their code.
Automation Engineers: Develop and maintain CI/CD pipelines, automation for testing, and deployment.
Security Specialists (DevSecOps): Integrate security into the pipeline, automate compliance checks, and ensure secure code deployment.
Core Responsibilities:
CI/CD Pipelines: Automate code testing, building, and deployment to production.
Continuous Feedback: Implement monitoring and logging tools like Prometheus and ELK Stack to give developers feedback on the performance and issues in production.
Automation: Reduce manual processes through infrastructure as code and automated configuration management (e.g., Ansible, Chef).
B. SRE (Site Reliability Engineering) Team
Primary Focus: Ensure system reliability and performance in production environments, balancing availability and change velocity.
Team Composition:
Site Reliability Engineers: Engineers responsible for setting and monitoring Service Level Objectives (SLOs), and implementing automation for maintaining uptime.
Incident Managers: Handle real-time incident response and coordinate across teams during outages.
Monitoring Experts: Implement and maintain real-time monitoring tools like Datadog and New Relic to track performance metrics and uptime.
Core Responsibilities:
SLO and SLA Management: Set and track SLOs based on business requirements (e.g., 99.99% uptime for mission-critical systems).
Error Budgets: Define thresholds for acceptable downtime and performance issues, ensuring a balance between innovation and system stability.
Incident Response: Own the process of on-call rotations, responding to incidents, diagnosing problems, and bringing systems back online.
Resilience Engineering: Conduct chaos engineering experiments using tools like Gremlin to test system resilience and fault tolerance.
C. Platform Engineering Team
Primary Focus: Build and maintain an internal platform that supports development teams with scalable, compliant infrastructure.
Team Composition:
Platform Engineers: Focus on designing internal platforms for self-service infrastructure and deployment automation.
Cloud Engineers: Manage cloud environments, automating infrastructure provisioning using Terraform and Pulumi.
Security and Compliance Engineers: Embed security and regulatory compliance into the platform, ensuring every deployment is secure and auditable.
Core Responsibilities:
Internal Developer Platforms (IDPs): Provide a self-service platform where development teams can easily create environments, deploy applications, and monitor their performance without needing direct operations involvement.
Infrastructure as Code (IaC): Use IaC tools like Terraform and AWS CloudFormation to standardize infrastructure, making it scalable, repeatable, and secure.
Security and Compliance: Ensure the platform complies with regulatory requirements (e.g., PCI DSS, GDPR), and integrate tools like HashiCorp Vault for secrets management.
Standardization and Abstraction: Abstract away the complexity of managing cloud environments, databases, and scaling infrastructure, so developers can focus on building features.
Operating Model Components
A. Governance and Compliance
Shared Responsibility Model:
Platform Engineering teams ensure the infrastructure is built with compliance in mind.
SRE ensures that incident response and monitoring are compliant with audit requirements.
DevOps integrates automated compliance checks into the CI/CD pipeline, ensuring code quality and security.
B. Collaboration and Communication
DevOps and SRE work closely together:
SRE helps define the SLOs that are achievable based on DevOps’ deployment velocity.
DevOps provides feedback from the development process to improve system reliability.
DevOps and Platform Engineering:
DevOps relies on Platform Engineering to ensure that infrastructure is stable and scalable.
Platform Engineering enables DevOps with tools for self-service deployments, making it easier to manage environments.
SRE and Platform Engineering:
SRE requires the platform to provide reliable environments, and Platform Engineering implements these with high availability and resilience in mind.
C. Automation and Tooling
CI/CD Pipelines: DevOps teams use GitLab CI, Jenkins, and CircleCI for continuous integration and delivery.
Monitoring and Incident Management: SREs rely on Prometheus, Datadog, and PagerDuty for real-time monitoring and alerts.
Infrastructure Provisioning: Platform engineers use Terraform and Pulumi to automate the provisioning of cloud resources.
Security and Compliance Tools: Tools like HashiCorp Vault for secrets management and Aqua Security for container security are integrated into both the platform and CI/CD pipelines.
Workflow and Process Design
A. Development Workflow (DevOps)
Code Development: Developers write new features, which are automatically tested using CI/CD pipelines.
Automated Testing: Continuous integration ensures that code is tested at every stage, including unit tests, integration tests, and security scans.
Automated Deployment: Once code passes the pipeline, it is automatically deployed to a staging environment for further testing.
B. Reliability and Incident Management (SRE)
Monitoring: SREs set SLOs and use monitoring tools to track system health and performance.
Error Budgets: If the error budget is exhausted, SREs work with development teams to prioritize fixes over new features.
Incident Response: In case of an outage, SREs trigger an incident response via PagerDuty, resolve the issue, and perform a post-incident review.
C. Platform Workflow (Platform Engineering)
Self-Service Infrastructure: Developers can provision environments, databases, and deploy services using the internal developer platform.
Infrastructure as Code (IaC): Changes to infrastructure are managed through code, allowing teams to version-control and review infrastructure changes.
Compliance and Security: The platform automatically enforces security policies, such as encryption standards and audit trails for regulatory compliance.
Success Metrics (KPIs)
DevOps KPIs:
Deployment Frequency: How often the team releases updates to production.
Lead Time for Changes: The time it takes for a code change to be committed and successfully deployed to production.
SRE KPIs:
Uptime/Availability: The percentage of time the system is available and meeting its SLOs.
Incident Response Time: The average time it takes for the SRE team to respond to and resolve incidents.
Error Budget Consumption: How much of the error budget has been used over a defined period.
Platform Engineering KPIs:
Developer Satisfaction: Measured via feedback on the internal platform’s ease of use.
Infrastructure Scalability: The ability of the platform to handle increased workloads without performance degradation.
Compliance and Audit Success: The number of successful compliance audits and the number of security incidents avoided.
Achieving Alignment Across Teams
This Target Operating Model ensures that DevOps, SRE, and Platform Engineering teams work in harmony to achieve common business goals. DevOps accelerates software delivery, SRE ensures system reliability, and Platform Engineering provides the infrastructure that makes it all possible. By focusing on collaboration, automation, and standardization, this TOM supports the company’s objectives of rapid innovation, high availability, and compliance in a complex technical environment.