

Large Language Models (LLMs) have revolutionized the field of Natural Language Processing (NLP) by enabling generative, interactive, and task-oriented AI applications. These models, trained on vast amounts of textual data, have emerged as foundational tools for various domains, from chatbots to content generation. This article provides a detailed overview of the key principles underlying LLMs, including pre-training, generative modeling, prompting techniques, and alignment methodologies.
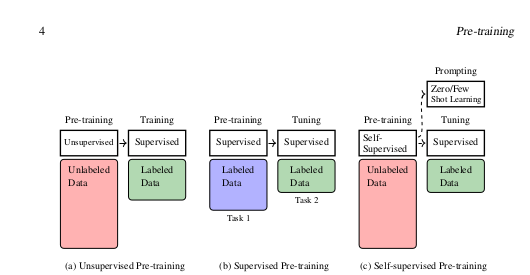
Pre-training forms the backbone of modern LLMs. The process involves training a neural network on massive datasets using self-supervised learning techniques. There are three main types of pre-training approaches:
These pre-training paradigms help LLMs acquire general linguistic capabilities, which can later be fine-tuned for specific tasks.
LLMs function primarily as generative models, predicting the next token in a sequence based on prior context. This process follows the probabilistic formulation:Pr(y∣x)=argmaxyP(y∣x)Pr(y|x) = \arg\max_y P(y | x)Pr(y∣x)=argymaxP(y∣x)
where xxx represents the input sequence and yyy denotes the predicted output. This autoregressive nature allows models to generate coherent, contextually relevant text. Popular generative architectures include:
Prompting is an essential mechanism for controlling LLM behavior without retraining. It involves crafting input instructions that elicit desired responses. Prominent prompting methods include:
Advanced prompting techniques, such as soft prompts (learned embeddings instead of text-based prompts) and ensemble prompting (combining multiple prompts), further enhance LLM performance.
LLMs must align with human values, expectations, and ethical considerations. This process is complex due to the diverse and evolving nature of human preferences. Poorly aligned models may generate biased, harmful, or misleading content.
Alignment ensures that LLMs not only generate accurate and useful outputs but also adhere to ethical standards.
Large Language Models are at the forefront of AI innovation, driven by pre-training, generative modeling, effective prompting, and careful alignment. While they offer transformative capabilities, challenges remain in improving their accuracy, ethical considerations, and adaptability. Continued research in these areas will refine LLMs, making them more robust and beneficial to society.
This article serves as a foundational guide to understanding LLMs and their key components. As advancements continue, further exploration into more efficient architectures, improved alignment techniques, and novel prompting strategies will shape the future of AI-driven language models.