Sur 20 ans d’expérience dans l’entreposage et l’ingénierie des données, on a pu observer l’évolution des architectures de données au sein des organisations. Selon un rapport d’IDC, le volume mondial de données devrait dépasser 175 zettaoctets d’ici 2025. Dans cette ère où les données sont au cœur des stratégies, les entreprises s’appuient sur des infrastructures robustes pour ingérer, transformer, enrichir et intégrer des volumes massifs d’informations.
Deux méthodologies majeures ont émergé pour répondre à ces besoins :
ETL (Extract, Transform, Load) – une approche traditionnelle pour l’intégration des données.
Les Pipelines de Données – un système moderne et flexible qui permet la gestion des données en temps réel et en mode batch.
Bien que ces concepts partagent des similitudes, leurs approches, leur flexibilité et leurs applications sont fondamentalement différentes. Cet article explore leurs définitions, différences clés et cas d’utilisation afin de vous aider à choisir la meilleure approche pour votre stratégie de données.
Qu’est-ce qu’un Pipeline de Données ?
Un pipeline de données est un système automatisé conçu pour transférer des données d’un système à un autre tout en réalisant, si nécessaire, des transformations. Contrairement à l’ETL, qui suit un processus structuré par lots, les pipelines de données prennent en charge à la fois le traitement en temps réel et par lots, et peuvent intégrer diverses sources et destinations.
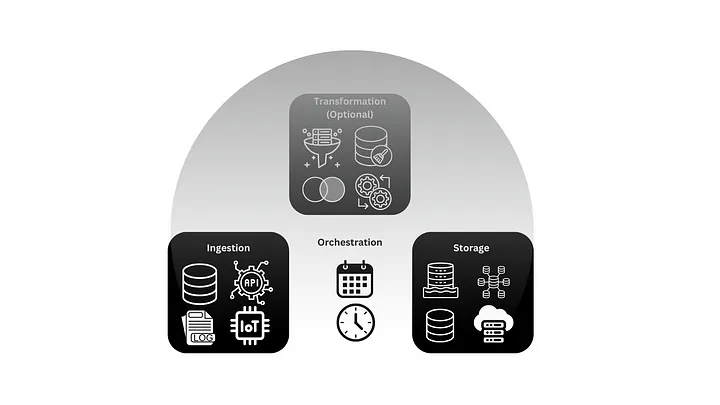
Principaux Composants d’un Pipeline de Données
Ingestion
Collecte des données à partir de sources variées : bases de données relationnelles, fichiers plats (CSV, JSON), API, objets connectés (IoT), logs applicatifs et plateformes de streaming comme Kafka.
Transformation (Facultatif)
Application de règles métier pour nettoyer, filtrer, enrichir et agréger les données afin de les rendre exploitables.
Stockage
Sauvegarde des données dans des systèmes intermédiaires ou finaux, tels que des data lakes, entrepôts de données, bases de données transactionnelles ou solutions cloud.
Orchestration
Gestion et planification des tâches pour assurer un flux de données fluide et automatisé.
Cas d’Utilisation des Pipelines de Données
Analytique en temps réel – Exemples : analyse des marchés boursiers, détection de fraudes.
Intégration des données multi-sources – Consolidation de flux de données hétérogènes.
Workflows d’IA/Machine Learning – Approvisionnement de modèles en données historiques et en temps réel.
Surveillance des systèmes – Agrégation des logs et supervision des performances.
Qu’est-ce que l’ETL (Extract, Transform, Load) ?
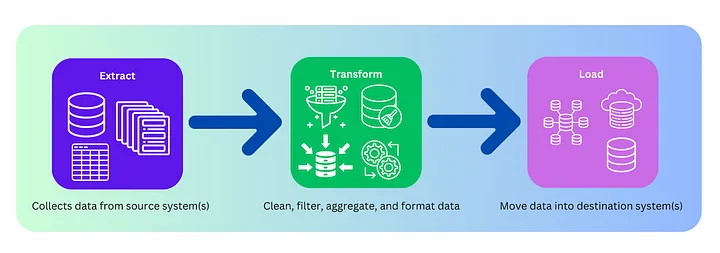
L’ETL est une méthodologie traditionnelle d’intégration des données, où les données sont extraites des systèmes sources, transformées selon des règles métier, puis chargées dans un entrepôt de données.
Étapes du Processus ETL
Extraction
Récupération des données depuis des bases de données, fichiers plats, API et systèmes hérités.
Transformation
Nettoyage, normalisation, enrichissement et agrégation des données pour répondre aux besoins du système cible.
Chargement
Dépôt des données traitées dans un entrepôt de données structuré, utilisé pour le reporting et l’analyse métier.
Cas d’Utilisation de l’ETL
Business Intelligence (BI) et reporting – Peuplement d’entrepôts de données structurés.
Migration de systèmes hérités – Transfert de données vers des plateformes modernes.
Conformité réglementaire – Standardisation des données pour respecter les réglementations.
Différences Clés Entre Pipeline de Données et ETL
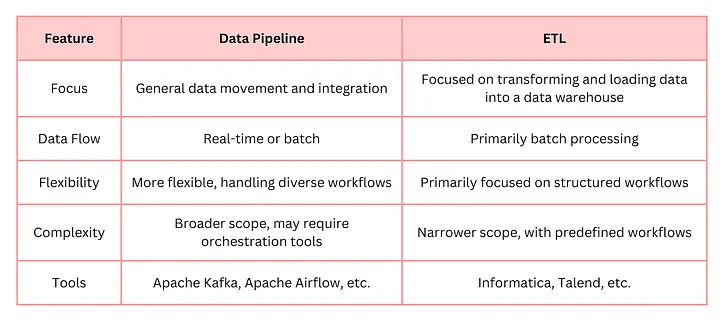
Alors que l’ETL se concentre sur un traitement structuré et par lots des données, les pipelines de données offrent une flexibilité accrue pour gérer des flux en temps réel et plus complexes. Voici un comparatif des différences principales :
Fonctionnalité
Pipeline de Données
ETL
Mode de Traitement
Prend en charge le streaming en temps réel et le traitement par lots
Orienté batch (traitement par lots)
Flexibilité
Gère des données structurées, semi-structurées et non structurées
Principalement conçu pour des données structurées
Cas d’Utilisation
Idéal pour l’analytique en temps réel, l’IA/ML, et l’architecture événementielle
Convient aux besoins de BI et d’entrepôts de données
Traditionnellement on-premise ou cloud entrepôts de données
Quand Utiliser un Pipeline de Données ?
Analytique en temps réel ou flux de données continus
Pour les cas où des informations immédiates sont nécessaires.
Workflows complexes avec sources et destinations multiples
Lorsque les données proviennent de sources variées (IoT, logs, bases de données, API, etc.).
Environnements modernes basés sur le cloud
Parfait pour les architectures serverless et les applications événementielles.
Quand Utiliser l’ETL ?
Besoins traditionnels en entreposage de données
Idéal pour le reporting et l’analyse métier.
Traitement batch de données statiques
Lorsque les mises à jour sont planifiées à intervalles réguliers.
Environnements hautement structurés
Fonctionne mieux avec des sources bien définies et prévisibles.
L’Approche Hybride : Combiner Pipeline de Données et ETL
Avec l’essor du cloud computing et du big data, de nombreuses entreprises adoptent une approche hybride, combinant les atouts des pipelines de données et de l’ETL pour une plus grande scalabilité et flexibilité.
Tendances Clés en Intégration des Données
ELT (Extract, Load, Transform)
Contrairement à l’ETL, l’ELT charge les données brutes dans un entrepôt cloud avant transformation, exploitant la puissance de calcul du cloud pour une meilleure évolutivité.
Frameworks Unifiés de Traitement des Données
Des outils open-source comme Apache Spark, Apache Flink et Kafka Streams permettent un traitement batch et streaming dans un même écosystème.
Solutions Cloud-Native
Des services comme AWS Glue, Google Cloud Dataflow et Azure Data Factory offrent des pipelines de données serverless avec auto-scaling.
Le Concept de Data Lakehouse
Fusion des data lakes et entrepôts de données, permettant de traiter à la fois les données structurées et non structurées.
Conclusion
Comprendre les différences entre les pipelines de données et l’ETL est essentiel pour concevoir des architectures de données performantes. Tandis que l’ETL reste incontournable pour les entrepôts de données structurés, les pipelines de données sont mieux adaptés aux environnements dynamiques et temps réel.
Avec l’évolution rapide des technologies, les entreprises doivent analyser leurs besoins spécifiques et s’appuyer sur des outils modernes pour bâtir des écosystèmes de données robustes et évolutifs.