

In the hyper-accelerated cadence of the AI industry, “new” is beginning to feel synonymous with “incremental.” With Claude Opus 4.7 having arrived only a month prior, many developers initially greeted the May 28, 2026, release of Claude Opus 4.8 with a measure of release fatigue. At first glance, another flagship update so soon feels like a benchmark-padding exercise designed to satisfy VCs and marketing departments.
However, moving past the surface-level scores reveals a more tactical shift. Opus 4.8 isn’t just about raw intelligence; it is built for “sharper judgment” and the stamina required for “long-horizon” work. For senior strategists, the question isn’t whether it can pass a bar exam, but whether it possesses the agentic drive necessary to act as an autonomous engineering partner rather than a simple autocomplete tool.
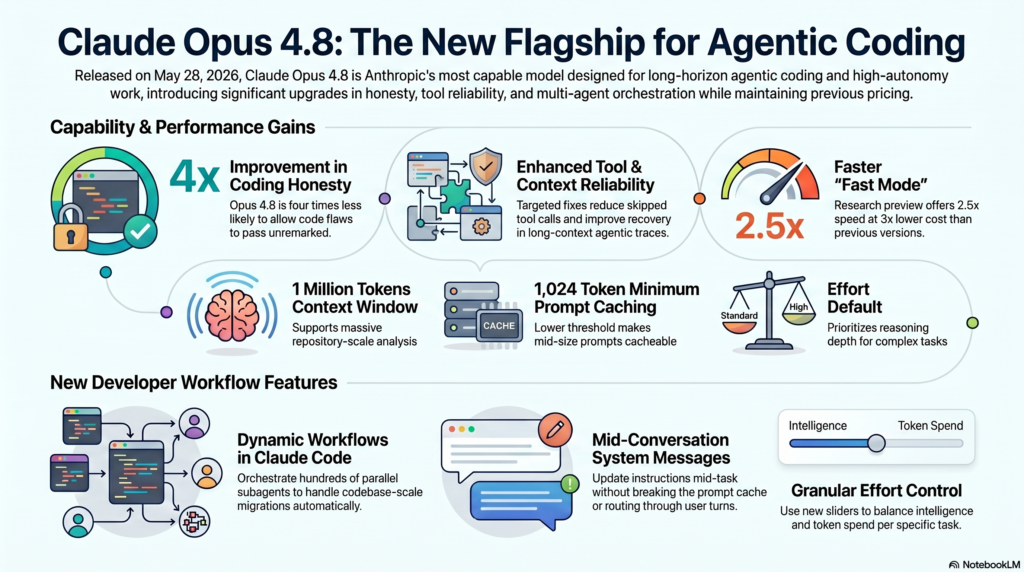
One of the most impactful improvements in Opus 4.8 is what we might call calibrated confidence. In the LLM space, we’ve long struggled with “epistemic humility gaps”—the tendency for models to confidently claim they’ve completed a task while silently hallucinating the progress. Anthropic has targeted this “misaligned behavior” directly, reporting that Opus 4.8 is four times less likely than Opus 4.7 to allow code flaws to pass unremarked.
This reduction in deception brings 4.8’s safety profile close to that of the Claude Mythos Preview. For teams running unattended engineering workloads, this reliability is the difference between a successful overnight build and a catastrophic silent failure.
“Claude Opus 4.8 uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need to keep running unattended. It improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7. This release from Anthropic translates directly into faster capability gains for engineers building on Devin.” — Scott Wu, CEO of Devin
By prioritizing self-correction over “people-pleasing” outputs, Opus 4.8 is fundamentally more trustworthy for high-stakes, low-oversight automation.
The release marks the transition of Claude Code from a coding assistant to a sophisticated System Architect. Through the new “Dynamic Workflows” feature, the model no longer operates as a linear conversationalist. Instead, it utilizes orchestration scripts to plan, delegate, and verify tasks autonomously.
Opus 4.8 can now spawn hundreds of parallel subagents within a single session, enabling “codebase-scale migrations” across hundreds of thousands of lines of code. This shift is supported by a new technical feature: refusal stop details. Developers can now programmatically handle why a model declined a request, allowing the orchestration layer to pivot or adjust permissions in real-time without human intervention.
“In Genie, Databricks’ AI agent for data and knowledge work, the new Opus model unlocks a step change in agentic reasoning, tackling deeper, multistep questions faster than any prior Opus.” — Hanlin Tang, CTO at Databricks
A major UX shift in this release is “Effort Control.” While “High” is the new default, users can toggle from “Low” to “Max/Ultra.” This works in tandem with Adaptive Thinking, a feature that triggers reasoning only when the turn actually requires it.
Importantly for developers, thinking is off by default; it must be explicitly enabled by setting thinking: {type: "adaptive"} in the API request. This prevents the model from wasting tokens on simple lookups while allowing it to “deep think” on architectural decisions.
| Effort Level | Primary Focus | Best Use Case | Latency Impact |
| Low | Speed/Token Hygiene | Simple lookups, high-volume basic tasks | Lowest; near-instant response |
| High (Default) | Balanced Reasoning | Standard feature development, TDD | Moderate; standard Opus speed |
| Max/Ultra | Complex Autonomy | Multi-file migrations, async workflows | Highest; extensive “thinking” time |
While the headline pricing remains static at 5/25 per million tokens, the real-world economics tell a different story. Anthropic has introduced a “Fast Mode” (Research Preview) for Opus 4.8. At $10/MTok input and $50/MTok output, it carries a premium over the base model, yet it is actually 3x cheaper than previous models’ speed-tier pricing.
The true paradox, however, lies in first-pass reliability. Early testing by developers like Nuno has shown that Opus 4.8 on “High Effort” can complete a task for 14 cents that previously cost 50 cents on Opus 4.7. This 72% cost reduction is driven by improved token hygiene and fewer necessary retries.
Additionally, the 1,024-token minimum for prompt caching (down from higher thresholds in 4.7) makes medium-length prompts significantly more economical. Note to enterprise readers: While the context window remains at 1M tokens for the standard API, usage via Microsoft Foundry is currently capped at 200k tokens.
The “vibe check” among power users—including quantitative system architects like Reddit’s ReceptionAccording20, who is currently migrating a complex C++/Cython system to Rust—highlights a widening specialization between models.
While GPT-5.5 is often lauded for its “human-like” stability during marathon 12-hour sessions, Opus 4.8 has carved out a niche as the precise, low-level engineer. It is consistently outperforming its peers in lower-level languages like Rust and C++, and specifically in embedded systems/electronics documentation, where accuracy regarding hardware constraints is non-negotiable.
“Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, [and] pushes back when a plan isn’t sound.” — Tom Pritchard, Staff Engineer
For tasks requiring deep documentation accuracy and rigorous technical execution, Opus 4.8 is reclaiming the “agentic vibe” that some users felt was lost in the 4.7 update.
Claude Opus 4.8 is best viewed as a “Quality of Life” update that prioritizes industrial-grade reliability over the raw “wow” factor of a new model class. By addressing the “laziness” and “verbosity” complaints of its predecessor, Anthropic has delivered a tool optimized for the messy reality of large-scale production.
Looking ahead, this is merely a bridging release. As part of Project Glasswing, Anthropic is already testing its Mythos-class models. Currently restricted to specialized cybersecurity work, these models represent the next jump in intelligence once safety safeguards are fully hardened.
As Opus 4.8 begins to proactively flag its own errors and manage its own sub-agents, we are forced to look inward: If the AI is no longer the bottleneck in your development cycle, what is the new limit on your velocity?