

Anthropic shipped Claude Fable 5 yesterday, and I want to be careful about how I talk about it, because the marketing temperature on model launches is now permanently set to “this changes everything.” Most of the time it doesn’t. This one is closer to actually mattering, and not entirely for the reasons the launch post leads with.
Here is the short version for busy people: Fable 5 is the first model from a new tier Anthropic calls Mythos-class, which sits above the Opus line. It is the most capable model they have ever made generally available. It is also the first model they have shipped with a hard safety wall bolted to the front of it, and that wall is going to show up in your day-to-day work whether you like it or not. Both of those facts are the story.
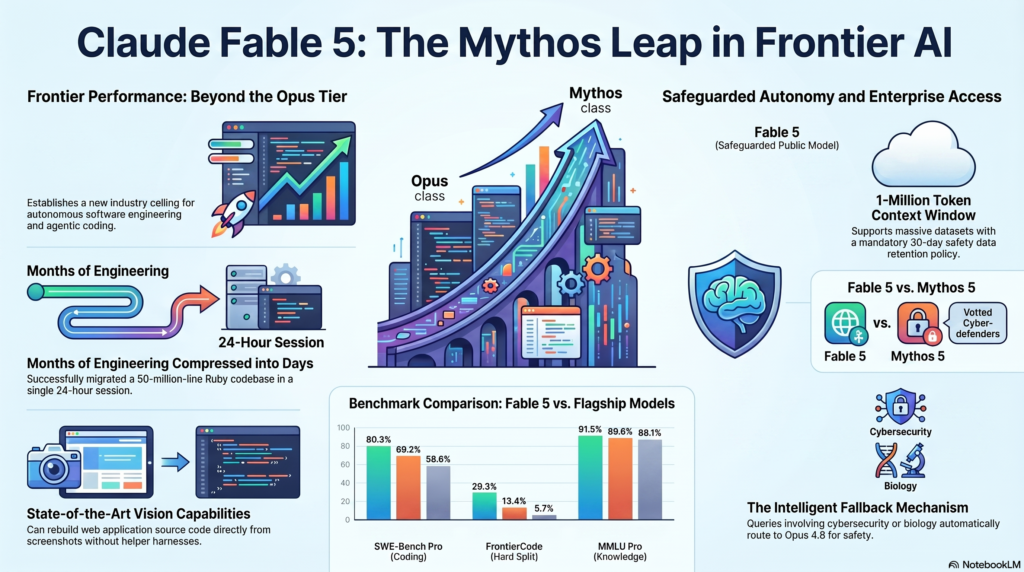
Anthropic has been running a program called Glasswing since April, where a small number of cyber-defense and critical-infrastructure partners got access to a model called Mythos Preview. The reason it was locked down is that the same model is unusually good at finding and exploiting software vulnerabilities, and they decided that was too dangerous to hand to everyone.
Fable 5 is that same underlying model, made public. The trick is in the name. Mythos 5 (still restricted to vetted partners) is the raw model. Fable 5 is Mythos 5 with safeguards in front of it. Same brain, different leash.
So when you read “first publicly available Mythos-class model,” what that means in practice is: you are getting frontier capability on most tasks, and a polite redirect on a narrow set of topics Anthropic considers high-risk.
On SWE-Bench Pro, which throws real engineering tasks from public GitHub repos at the model with no hand-holding, Fable 5 lands at 80.3%. For comparison, Opus 4.8 sits at 69.2%, GPT-5.5 at 58.6%, and Gemini 3.1 Pro at 54.2%. That is a real gap, not a rounding error.
The one that got my attention is Cognition’s FrontierCode, which checks whether a model can pass hard coding tasks while meeting production-codebase standards. Fable 5 scores 29.3%. Opus 4.8 manages 13.4%. GPT-5.5 gets 5.7%. The absolute numbers are low because the benchmark is brutal, but the relative jump is the interesting part. Roughly double Opus on the kind of task that actually resembles your job.
The anecdote Anthropic is leaning on hardest: Stripe ran it against a 50-million-line Ruby codebase and had it do a codebase-wide migration in a day that they estimate would have taken a team over two months by hand. Take vendor-supplied customer stories with the usual grain of salt, but the shape of the claim (long, tedious, mechanical refactors at scale) is exactly where these models earn their keep, so I find it plausible.
Two things matter more to me than any single benchmark. First, it is more token-efficient than past Claude models, finishing in fewer turns. On long agentic runs that is the difference between a tool you trust to keep going and one you babysit. Second, it holds up over long-horizon tasks. The lead over Opus reportedly widens the longer and more complex the task gets, which tracks with what these models have historically been worst at.
Vision got a genuine upgrade too. It can reconstruct a web app’s source from screenshots alone, and it cleared Pokémon FireRed with a vision-only setup, where earlier models needed a pile of helper scaffolding to play at all. If your work touches UI-to-code, design handoff, or reading information out of charts and scientific figures, that is worth a look.
Here is the thing nobody is going to put in a launch graphic. When Fable 5’s classifiers detect a request touching cybersecurity, biology and chemistry, or model distillation, your prompt does not go to Fable. It silently falls back to Opus 4.8, and you get told it happened.
Anthropic says this triggers in under 5% of sessions, and that more than 95% of sessions see no fallback at all. Fine. But they also admit the classifiers are tuned conservatively on purpose, which is a careful way of saying they will catch harmless requests. If you do security work, write anything that smells like offensive tooling, do pentesting, or work in biotech, you are going to hit this wall more than the average user, and you will hit it on legitimate work.
I have mixed feelings here, and I am not going to pretend otherwise. The reasoning is defensible. A model this good at finding exploits is a real proliferation risk, and “fall back to a still-excellent model” is a far better failure mode than a flat refusal. But conservative classifiers mean some of you will pay a productivity tax on work that was never dangerous. Budget for it. If your workflow lives in one of those zones, do not architect around Fable 5 being available for every call.
One more operational detail that will matter to anyone in a regulated shop: Anthropic is now requiring 30-day data retention on all Mythos-class traffic, first-party and third-party. They say it will not be used for training and gets deleted after 30 days, and the stated purpose is catching novel attacks and jailbreaks. If your compliance posture assumed zero-retention, check this before you wire Fable into anything that touches sensitive data.
Fable 5 is $10 per million input tokens and $50 per million output tokens. That is close to double what Opus 4.8 costs. For one-shot reasoning that would have taken Opus several attempts, the math can still come out ahead because of the fewer-turns efficiency. For high-volume, low-difficulty calls, it almost certainly does not. Route deliberately. This is not a “swap the model string everywhere” upgrade.
Now the part that will catch people. The subscription rollout is staged, and there is a cliff. Through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost. On June 23, they pull it from those plans, and using it after that needs usage credits. They say they intend to restore it as a standard plan feature once capacity allows, with no firm date.
So if you are evaluating it on a subscription right now, you are inside a free window that closes in twelve days. Do your serious testing before June 23, or you will go to reach for it mid-sprint and find it behind a paywall you did not plan for. On the API and consumption-based Enterprise plans it is fully available today with no window games. The model string is claude-fable-5.
This is the most capable model you can put your hands on today, and the coding and long-horizon agentic gains are real enough that I would not call the hype empty this time. The Stripe-style mass refactor, the long autonomous runs that do not drift, the vision work: that is a meaningful step, not a point release.
But the launch is also the clearest signal yet that we have entered the era where the most capable model and the model you are allowed to use are no longer the same thing. Fable is Mythos with a leash, and the leash is going to chafe for a real slice of this audience. That is a deliberate trade, made by a company that spent last week publicly warning that frontier AI is getting dangerous, and you should read the safeguards as them meaning it rather than as a temporary inconvenience.
If you write code for a living, test it this week while it is free, route it by task rather than by default, and watch your fallback rate. If you work in security or bio, go in expecting friction. And if you run infrastructure, read the retention policy before anyone on your team gets excited.
Capability went up. So did the number of asterisks. Plan for both.
https://www.anthropic.com/news/claude-fable-5-mythos-5