

Comprenez les principales différences entre Data Pipeline et ETL Pipeline , les cas d’utilisation et les meilleures pratiques pour le traitement des données en temps réel et l’intégration des données par lots.
De nos jours, les données sont un facteur clé de succès pour de nombreux systèmes d’information. Pour exploiter ces données, elles doivent être déplacées et collectées à partir de nombreuses sources différentes, en utilisant diverses technologies et outils.
Il est important de comprendre la différence entre un pipeline de données et un pipeline ETL. Bien que les deux soient conçus pour déplacer des données d’un endroit à un autre, ils ont des objectifs différents et sont optimisés pour des tâches distinctes. Le tableau comparatif ci-dessous met en évidence les principales différences :
| Caractéristique | Pipeline de données | Pipeline ETL |
|---|---|---|
| Mode de traitement | Traitement en temps réel ou quasi réel | Traitement par lots à intervalles planifiés |
| Flexibilité | Très flexible avec divers formats de données | Moins flexible, conçu pour des sources de données spécifiques |
| Complexité | Complexe lors de la transformation mais plus simple en mode batch | Complexe lors de la transformation mais plus simple en mode batch |
| Scalabilité | Facilement évolutif pour les données en flux continu | Évolutif mais gourmand en ressources pour les grandes tâches par lots |
| Cas d’utilisation | Analytique en temps réel, applications pilotées par des événements | Entrepôt de données, analyse des données historiques |
Un pipeline de données est un processus systématique permettant de transférer des données d’un système à un autre, souvent en temps réel ou quasi réel. Il permet un flux et un traitement continus des données entre les systèmes. Ce processus implique de collecter des données provenant de multiples sources, de les traiter pendant qu’elles transitent dans le pipeline, puis de les livrer aux systèmes cibles.
Les pipelines de données sont conçus pour gérer l’intégration fluide et le flux de données à travers différentes plateformes et applications. Ils jouent un rôle crucial dans les architectures de données modernes en permettant l’analytique en temps réel, la synchronisation des données et le traitement piloté par des événements. En automatisant les processus de mouvement et de transformation des données, les pipelines de données aident les organisations à maintenir la cohérence et la fiabilité des données, à réduire la latence et à s’assurer que les données sont toujours disponibles pour les opérations commerciales et la prise de décision critiques.
Les pipelines de données gèrent des données provenant de diverses sources, notamment :
Les pipelines de données peuvent traiter des données en temps réel ou quasi réel. Cela implique de nettoyer, enrichir et structurer les données au fur et à mesure qu’elles transitent dans le pipeline. Par exemple, les données en flux provenant des appareils IoT peuvent nécessiter une agrégation et un filtrage en temps réel avant d’être prêtes pour l’analyse ou le stockage.
L’étape finale d’un pipeline de données consiste à livrer les données traitées à leurs systèmes cibles, tels que des bases de données, des lacs de données ou des plateformes d’analytique en temps réel. Cette étape garantit que les données sont immédiatement accessibles à plusieurs applications et fournissent des informations instantanées permettant une prise de décision rapide.
Les pipelines de données sont essentiels dans les scénarios nécessitant un traitement continu ou en temps réel des données.
Les cas d’utilisation courants incluent :
Les pipelines de données sont souvent utilisés avec des modèles architecturaux tels que CDC (Change Data Capture), le modèle Outbox, ou CQRS (Command Query Responsibility Segregation).
Les pipelines de données offrent plusieurs avantages, mais présentent également des défis propres au traitement des données en temps réel.
Avantages
Inconvénients
L’ETL, qui signifie Extract, Transform, and Load (Extraction, Transformation, Chargement), est un processus utilisé pour extraire des données de différentes sources, les transformer dans un format approprié, puis les charger dans un système cible.
Un programme ETL peut collecter des données à partir de diverses sources telles que des bases de données, des API, des fichiers, et plus encore. La phase d’extraction est séparée des autres phases pour rendre les étapes de transformation et de chargement indépendantes des changements dans les sources de données.
Une fois la phase d’extraction terminée, la phase de transformation commence. Cette étape consiste à restructurer les données pour garantir qu’elles sont adaptées à leur utilisation prévue. Les données provenant de différentes sources et formats doivent souvent être nettoyées, enrichies ou normalisées. Par exemple, les données destinées à une visualisation peuvent nécessiter une structure différente des données collectées à partir de formulaires en ligne. La transformation garantit que les données sont prêtes pour l’étape suivante.
La phase finale du processus ETL consiste à charger les données transformées dans le système cible, tel qu’une base de données ou un entrepôt de données. Pendant cette phase, les données sont écrites dans le système cible de manière optimisée pour les performances de requêtes et de récupération.
Les processus ETL sont essentiels dans divers scénarios où les données doivent être consolidées et transformées pour une analyse significative.
Les cas d’utilisation courants incluent :
Avantages
Inconvénients
Comprendre les principales différences entre les pipelines de données et les pipelines ETL est essentiel pour choisir la bonne solution en fonction de vos besoins de traitement de données. Voici les principales distinctions :
Les pipelines de données fonctionnent en temps réel ou quasi réel, en traitant continuellement les données à mesure qu’elles arrivent, ce qui est idéal pour les applications nécessitant des informations immédiates. En revanche, les pipelines ETL traitent les données par lots à des intervalles planifiés, ce qui entraîne des délais entre l’extraction des données et leur disponibilité.
Les pipelines de données sont très flexibles, pouvant gérer plusieurs formats de données et sources tout en s’adaptant aux flux de données changeants en temps réel. Les pipelines ETL, quant à eux, sont moins flexibles, conçus pour des sources et formats de données spécifiques, nécessitant des ajustements importants en cas de modifications.
Les pipelines de données sont complexes à configurer et à maintenir en raison de la nécessité d’un traitement en temps réel et d’une surveillance continue. Les pipelines ETL sont également complexes, surtout lors de la transformation des données, mais leur traitement par lots les rend un peu plus faciles à gérer.
Les pipelines de données évoluent facilement pour gérer de grands volumes de données en flux continu et s’adaptent aux charges variables en temps réel. Les pipelines ETL peuvent évoluer pour des tâches de traitement par lots importantes, mais nécessitent souvent des ressources et une infrastructure significatives, les rendant plus gourmands en ressources.
Pour mieux comprendre les applications pratiques des pipelines ETL et des pipelines de données, examinons quelques exemples concrets qui illustrent leur utilisation dans des scénarios réels.
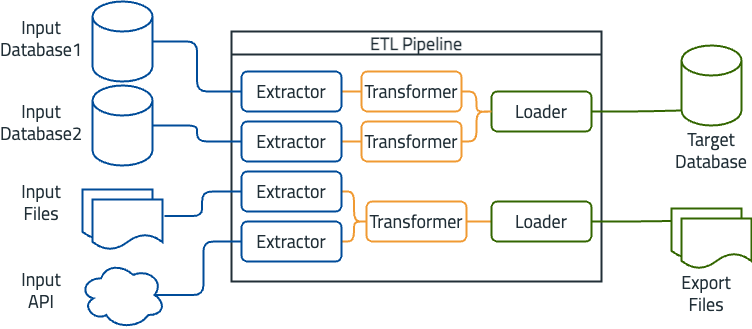
Un exemple de pipeline ETL est un entrepôt de données pour les données de vente. Dans ce scénario, les sources d’entrée incluent plusieurs bases de données qui stockent des transactions commerciales, des systèmes CRM et des fichiers plats contenant des données historiques de ventes. Le processus ETL consiste à extraire les données de toutes ces sources, à les transformer pour garantir leur cohérence et leur précision, puis à les charger dans un entrepôt de données centralisé. Le système cible, dans ce cas, est un entrepôt de données optimisé pour l’intelligence d’affaires et la création de rapports.
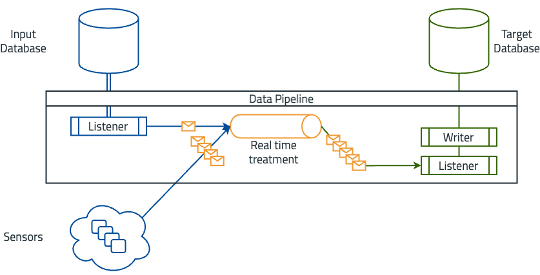
Un exemple courant de pipeline de données est le traitement des données de capteurs en temps réel. Les capteurs collectent des données qui doivent souvent être agrégées avec des données de base de données standard. Dans ce cas, les sources d’entrée incluent des capteurs produisant des flux de données continus et une base de données d’entrée. Le pipeline de données se compose d’un écouteur qui collecte les données des capteurs et de la base de données, les traite en temps réel et les transfère vers la base de données cible. Le système cible est une plateforme d’analytique en temps réel qui surveille les données des capteurs et déclenche des alertes.
Le choix entre un pipeline de données et un pipeline ETL pour votre organisation dépend de plusieurs facteurs. Les caractéristiques des données sont un critère clé dans cette décision. Les pipelines de données sont idéaux pour les flux de données continus en temps réel qui nécessitent un traitement et des informations immédiates. Les pipelines ETL, en revanche, conviennent mieux aux données structurées pouvant être traitées par lots, lorsque la latence est acceptable.
Les exigences commerciales jouent également un rôle important. Les pipelines de données sont parfaits pour les cas d’utilisation nécessitant une analyse des données en temps réel, comme la surveillance, la détection de fraudes ou les rapports dynamiques. À l’inverse, les pipelines ETL conviennent mieux aux scénarios nécessitant une consolidation extensive des données et une analyse historique, comme les entrepôts de données et l’intelligence d’affaires.
Les besoins en scalabilité doivent également être pris en compte. Les pipelines de données offrent une haute scalabilité pour le traitement en temps réel et peuvent gérer efficacement les volumes de données fluctuants. Les pipelines ETL sont évolutifs pour les tâches de traitement par lots, mais peuvent finalement nécessiter plus d’infrastructure et de ressources.
Le choix entre un pipeline de données et un pipeline ETL dépend de vos besoins en matière de données et de vos objectifs commerciaux. Les pipelines de données excellent dans les scénarios qui nécessitent un traitement des données en temps réel et des informations immédiates, tandis que les pipelines ETL sont conçus pour le traitement par lots et l’analyse historique. Comprendre ces différences vous aidera à choisir la meilleure approche pour optimiser votre stratégie de données.
Chang, K. (2021). Data Pipelines in Modern Analytics: Best Practices and Strategies. DataTech Publications.
Martin, J. (2020). “Real-Time Data Processing and Its Benefits in Event-Driven Systems”. Journal of Data Engineering, 45(2), 112-128.
Smith, P. & Lewis, R. (2019). The Evolution of ETL Pipelines: From Batch Processing to Continuous Data Flows. Cambridge University Press.
Brown, L. (2022). “Data Warehousing with ETL Pipelines: Key Techniques for Large Scale Data Integration”. Data Science Review, 39(4), 55-70.
García, E. (2020). Optimizing Data Pipelines for Scalability: A Guide for Data Engineers. O’Reilly Media.
Verma, A. (2021). “Understanding ETL Pipelines in Business Intelligence Applications”. Information Systems Journal, 38(1), 91-105.
Introduction to Data Pipelines and Their Importance in Real-Time Analytics
ETL vs. Data Pipelines: Key Differences and Use Cases
Best Practices for Building Scalable Data Pipelines
Understanding Continuous Data Processing with Real-Time Data Pipelines