

From Code to Weights to Prompts: A Practitioner’s Guide to Software 3.0
By Sami BELHADJ
In the past three years, software development has hit an inflection point unlike anything the industry has seen since the transition from mainframes to personal computing. Large language models have exploded in popularity at a pace that caught even their creators off guard. ChatGPT reached 100 million users by January 2023, setting the record for the fastest user adoption of any technology in history. Enterprises have scrambled to keep pace: surveys indicate that 72% of companies plan to increase their AI spending in 2025. AI-driven coding assistants like GitHub Copilot have crossed 20 million users and are now embedded in the workflows of 90% of Fortune 100 companies.
This is not a passing trend. We are witnessing a fundamental paradigm shift—often called “Software 3.0”—in how software is conceived, built, and deployed. Senior engineers are no longer just writing code or training models; they are increasingly instructing AI systems in natural language to accomplish complex tasks. English—not Python, not Java—is becoming the programming interface of this new era.
This post explores the full arc of that transformation. It traces the journey from deterministic code to learned weights to natural language prompts, examines the strange psychology of the models powering this shift, and offers practical frameworks for building production-ready systems in a world where AI is no longer a feature—it is the foundation.
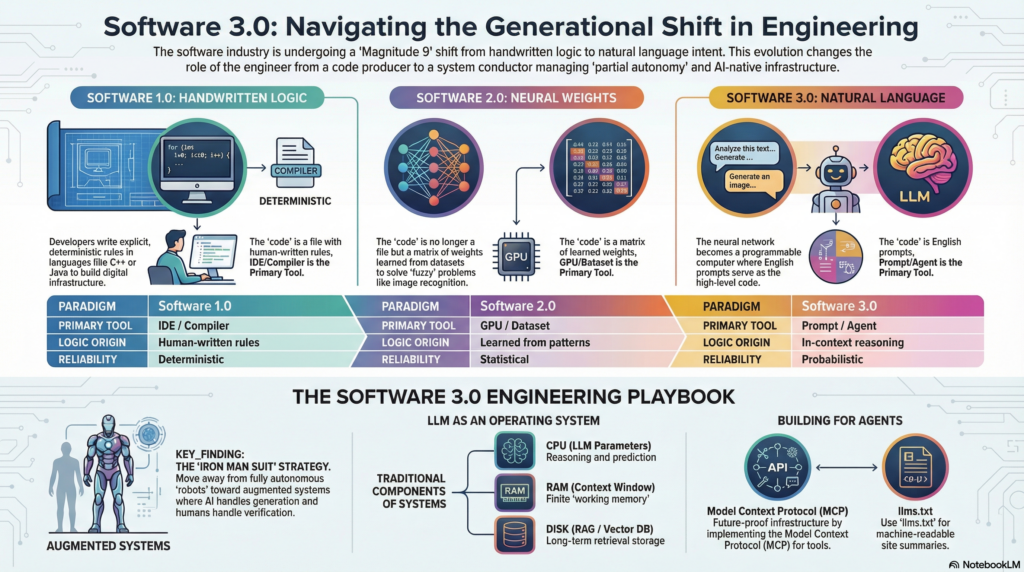
To navigate this new landscape, we first need to understand the three distinct eras of software creation. Each represents a fundamentally different relationship between the developer and the machine.
For seven decades, the dominant paradigm was manual, deterministic coding. Programmers wrote explicit instructions in languages like C++, Java, and Python. Every behavior was a direct reflection of human thought—defined through loops, conditionals, and data structures. If you wanted a sentiment analyzer, you wrote a rule-based classifier with string matching, keyword lexicons, and carefully tuned heuristics.
This approach built the digital infrastructure of the modern world: banking systems, operating systems, web browsers, and enterprise applications. It was reliable and predictable. The trade-off was scalability of logic: as problem complexity grew, the human capacity to manage edge cases became the binding constraint. Tasks like image recognition or natural language understanding—where the rules are too numerous and fuzzy to enumerate—remained largely intractable.
The deep learning revolution changed the primary artifact of development from source code to model weights. Instead of writing logic, engineers curated datasets and ran optimizers to discover the millions or billions of parameters that minimized a loss function. The “code” was no longer a file you edited in an IDE—it was a matrix of floating-point numbers learned from patterns in data.
A compelling case study is Tesla’s Autopilot stack. Initially, the system relied heavily on hand-written C++ code for tasks like multi-camera image stitching and lane detection. As neural networks matured, they progressively replaced that logical code with learned behavior. Temporal modules and Bird’s-Eye View predictions that were previously impossible to hard-code became achievable through training. Software 2.0 literally ate through the Software 1.0 stack.
Software 3.0 represents the most radical leap yet: the neural network has become a programmable computer. While Software 2.0 models like AlexNet were fixed-function classifiers, Software 3.0 models (LLMs) are general-purpose processors that can be reconfigured through natural language prompts.
Consider the sentiment classification example across all three paradigms. In Software 1.0, you write a Python keyword lexicon. In Software 2.0, you train a binary classifier on 20,000 labeled examples. In Software 3.0, you provide a few-shot prompt in English defining the rules and desired output format. The model executes it. This shift is not merely a convenience—it is a fundamental change in the programmable substrate of the industry.
| Paradigm | Primary Tool | Logic Origin | Reliability Pattern |
| Software 1.0 | IDE / Compiler | Human-written rules | Deterministic |
| Software 2.0 | GPU / Dataset | Learned from patterns | Statistical accuracy |
| Software 3.0 | Prompt / Agent | In-context reasoning | Probabilistic / Semantic |
Crucially, these three layers coexist. Software 3.0 does not eliminate the need for traditional code or trained models. Instead, it sits atop them, gradually absorbing functions that were previously hand-crafted. Over time, many traditional software tasks are being reimagined as “prompt + completion” workflows, often with dramatically less manual engineering. Software 3.0 is eating Software 1.0 and 2.0.
The most striking implication of Software 3.0 is that the prompt is now the program. Natural language has become the dominant interface for instructing machines. This is not merely a change in syntax—it is a philosophical inversion. For the first time in computing history, the barrier between human intent and machine execution has collapsed to a conversation.
Consider what this means in practice. A product manager who once needed to file a Jira ticket and wait for a sprint cycle can now describe a feature to an LLM and see a working prototype in minutes. A data analyst can write complex SQL transformations by simply describing the desired output in plain English. A marketing team can generate A/B test variations of landing pages without writing a single line of HTML.
But this democratization comes with a crucial caveat. Natural language is inherently ambiguous. The same prompt can produce different outputs depending on the model, the context window state, and even the random seed. This means that while the barrier to entry has plummeted, the barrier to reliability has shifted. The challenge is no longer writing code that compiles—it is writing prompts that consistently produce correct, safe, and predictable behavior at scale.
For senior engineers, this represents a new domain of expertise. Prompt engineering is not just “typing instructions”—it involves understanding tokenization, context window management, few-shot learning dynamics, and the subtle ways in which LLMs interpret (and misinterpret) instructions. The skill is moving from syntax mastery to intent precision.
To understand the economics and architecture of the AI era, it helps to view LLMs through three complementary lenses: as utilities, as fabrication plants, and as operating systems.
LLMs are increasingly consumed like electricity. Companies don’t build their own power plants; they plug into the grid. Similarly, most organizations will not train frontier models. They will consume intelligence through API calls to providers like OpenAI, Anthropic, or Google. This utility model offers incredible convenience but introduces a novel vulnerability: intelligence brownouts. When a major API provider goes down, the effect is not limited to a single product—the world’s cognitive supply is interrupted. Global productivity stalls because the intelligence supply to the planet is temporarily cut off.
This creates profound economic and strategic questions. Traditional software favored high upfront costs with low marginal costs per user. Software 3.0 inverts this: the upfront development cost is dramatically lower (you write prompts instead of code), but the marginal cost per interaction rises because every query consumes tokens and inference compute. Engineering leaders must navigate this new cost structure carefully.
On the hardware side, training frontier models is comparable to building a semiconductor fabrication plant. A cluster of 100,000 high-end GPUs—like the massive training clusters built by leading AI labs—represents a multi-billion-dollar capital investment. This creates deep R&D moats. Companies without such scale become “fabless” AI developers, innovating at the application layer on top of centralized models, much like ARM-based chip designers innovate without owning foundries.
Perhaps the most powerful analogy is that LLMs are evolving into a new class of operating systems. Unlike physical infrastructure, LLMs are software—they are easy to copy, update, fork, and even open-source. As a kernel manages memory and processes in a traditional OS, an LLM now manages “memory” and processes for AI applications.
The technical parallels are striking. The context window of an LLM is its RAM. At 128,000 tokens, a model like GPT-4’s context window is roughly equivalent to 640 KB of working memory—eerily reminiscent of the early computing era. The internet or a vector database becomes the LLM’s disk, from which it pages information in and out of context as needed. We still interact primarily through text chat, which is effectively a terminal interface—a true AI GUI has yet to be invented.
| OS Concept | LLM Equivalent | Implication |
| RAM | Context Window | Finite working memory for prompt state |
| Disk | RAG / Vector DB | Long-term retrieval-based storage |
| Kernel | System Prompt | Orchestration of tool calls and I/O |
| Terminal | Chat Interface | Direct native access to the “OS” |
In this analogy, we are living in the mainframe era of AI—the 1960s. A few centralized “supercomputers” serve all of us via time-sharing. The personal computer revolution of AI, where models run locally and are personalized to each user, is still on the horizon.
There is one more structural anomaly worth noting. Traditionally, transformative technologies diffused from institutions to individuals. The internet started as a military project (ARPANET), moved to universities, then enterprises, and finally reached consumers. GPS, flight, and nuclear energy followed similar trajectories.
LLMs have flipped this script entirely. ChatGPT became the fastest-growing consumer application in history, reaching hundreds of millions of weekly users before most corporations had figured out their security protocols. Individuals now carry a cognitive supercomputer in their pocket, while many institutions remain mired in legacy systems and regulatory inertia. For the first time, technology has reached the individual before the enterprise. This inversion has profound implications for how AI-native products will be built and adopted.
LLMs are not traditional programs. They are stochastic simulations of people—trained on the sum of human expression, they have developed an emergent and often paradoxical psychology. Understanding this psychology is not a theoretical exercise; it is a prerequisite for building reliable systems.
LLMs exhibit what researchers call “jagged intelligence.” They can perform astonishing feats of reasoning and knowledge retrieval in one domain while failing spectacularly at tasks that a child could handle in another. A model might write a sophisticated distributed systems design document while simultaneously making a basic arithmetic error. This jaggedness is not a bug that will be patched—it is a structural property of how these models process information.
For engineering teams, this means that confidence does not equal correctness. An LLM will deliver a wrong answer with the same authoritative tone as a right one. The system does not “know” when it is wrong. This asymmetry demands robust verification layers in any production deployment.
Two of the most critical cognitive quirks are hallucination—the model’s tendency to confidently state false facts—and gullibility. Because instructions (the system prompt) and data (user input) are processed in the same natural language stream, LLMs struggle to maintain security boundaries. This is the “NX bit” problem of the AI era: we lack a hardware-enforced mechanism to separate executable instructions from untrusted data. Any user input can potentially hijack the system prompt through prompt injection.
Senior engineers must therefore treat LLMs as privileged but untrusted components that require extensive sandboxing. The mitigation strategies involve grounding outputs in external documentation and citations, implementing multi-layer input validation, and designing systems where the LLM’s outputs are always subject to programmatic verification before they reach the user or trigger actions.
LLMs also suffer from the “reversal curse”—they may know that A implies B without being able to infer that B implies A. If a model is trained on the fact that “Alice’s phone number is 555-1234,” it may not be able to answer “Who has the phone number 555-1234?” This reveals a fundamental asymmetry in how associative memory works within these models, and it has practical implications for knowledge retrieval and reasoning chain design.
Furthermore, while LLMs have impressive context windows, they have no persistent memory between sessions by default. There is currently no pathway from a model’s temporary context to its permanent weights during inference. Every conversation starts from a blank slate unless the application explicitly manages state through retrieval systems or conversation history.
The most successful AI applications today do not aim for full autonomy. Instead, they operate in the realm of partial autonomy—functioning as sophisticated assistants that augment human capability rather than replacing it. This is not a limitation to be apologized for; it is the correct design pattern for the current era.
A modern LLM application is not just a chat window. It is a complex orchestration layer built around three core functions. First, context packaging: automatically gathering and feeding relevant information (open files, related documentation, user history) into the model’s context window. Second, multi-LLM orchestration: routing different subtasks to specialized models (an embedding model for search, a reasoning model for logic, a code-generation model for diffs). Third, custom GUIs: purpose-built interfaces that allow humans to verify AI outputs faster than they could through raw text.
Cursor, the AI-powered code editor, is the exemplar of this pattern. It doesn’t just generate code in a chat window—it manages code diffs, state packaging, and visual audits that engineers can instantly accept or reject. The interface is designed around the principle that the bottleneck is human verification, not machine generation.
A crucial UX concept is the autonomy slider—not a binary toggle but a dynamic scale of trust. At Level 1 (Operator), the agent only acts on explicit commands; it is essentially an advanced autocomplete. At Level 3 (Consultant), the agent plans multi-step workflows but waits for human approval before executing. At Level 5 (Observer), the agent operates fully autonomously, merely surfacing logs for review. The most effective products allow users to adjust this slider mid-task, handing over more control as the agent earns trust through verifiable performance.
| Autonomy Level | Role of LLM | Role of Human | UI/UX Focus |
| Level 1: Operator | Waits for command | Driver / Coder | Hotkeys / Input fields |
| Level 3: Consultant | Plans & proposes | Manager / Approver | Action cards / Previews |
| Level 5: Observer | Fully autonomous | Passive Auditor | Activity logs / Check-ins |
Additionally, teams are implementing the “LLM-as-a-Judge” pattern to maintain reliability at scale. Instead of relying solely on slow, expensive human review, a powerful “judge” model evaluates the quality, factual correctness, and safety of a “generator” model’s output against a strict rubric. This creates a scalable feedback loop that allows teams to iterate on prompts and architectures far faster than traditional testing methods.
The central engineering principle of Software 3.0 is deceptively simple: the fundamental limit of productivity is not how fast the machine can generate, but how fast the human can verify. This is the Generation-Verification loop, and optimizing it is the single most important design decision in any LLM-powered application.
The loop works as follows. The AI generates a small, scoped output—a code diff, a paragraph, a data transformation. The human reviews it through a purpose-built interface designed for speed: visual diffs, syntax highlighting, color-coded changes. If correct, the human accepts and moves on. If incorrect, the human provides feedback, and the cycle repeats. The faster this loop turns, the more productive the human-AI team becomes.
The implication is that AI outputs should be small and verifiable, not large and impressive. An LLM that refactors ten files simultaneously may seem powerful, but if the developer spends hours reviewing the massive diff, the productivity gain evaporates. The discipline of “keeping the AI on a tight leash”—breaking large tasks into smaller, verifiable steps—prevents the model from generating unmanageable outputs that are prone to subtle bugs.
This principle also reshapes what it means to be a senior engineer. The value is no longer in typing speed or syntax knowledge—it is in judgment: the ability to craft good prompts, design verification architectures, set up safety checks, and steer AI execution toward correct outcomes. Code review is becoming more important than code writing. In a world where AI generates most of the code, engineers who can evaluate that code’s correctness, security, and maintainability become exponentially more valuable.
The history of autonomous vehicles provides a sobering and instructive lesson for the current wave of AI agent enthusiasm. Turning an autonomy demo into a reliable product requires orders of magnitude more engineering work than the demo itself.
The key insight is captured in a single aphorism: a demo is works.any(), a product is works.all(). A demo only needs to work once under controlled conditions. A product must work consistently across all conditions, including edge cases that the designer never anticipated. Early self-driving demonstrations looked impressively capable, but the gap between a flawless demo in a controlled environment and a system that handles every intersection, weather condition, and unpredictable pedestrian in the real world has taken over a decade to close—and it remains open.
Tesla’s approach to this gap offers a design template for AI applications. Rather than waiting for full Level 5 autonomy, Tesla incrementally deployed capabilities through an autonomy slider: lane keeping, highway autopilot, traffic light recognition, intersection turns. Users could dial up features as trust grew. Each increment generated data that improved the next iteration. The human driver remained the ultimate safety layer throughout.
This gradual approach maps directly onto how we should deploy LLM-powered features. Start with manual mode, then move to suggestions, then to supervised automation, then to full autonomy in narrow domains. Build trust through demonstrated reliability, not through ambitious promises. The “decade of driving agents” from 2015 to 2025 is now being followed by what will likely be a “decade of software agents” from 2025 to 2035. Patience and incrementalism are not weaknesses—they are engineering virtues.
The future of AI in software is not about building Iron Man robots that replace humans. It is about building Iron Man suits that enhance them.
An autonomous robot operates independently and is vulnerable to catastrophic failure when it encounters novel situations. An exoskeleton enhances the user’s strength, speed, and intelligence while keeping their judgment and domain expertise at the center. For individuals, LLMs act as a major multiplier to their capabilities. They provide quasi-expert knowledge that allows a developer to rapidly absorb a new technology, a lawyer to draft a complex brief, or a product manager to prototype a feature—all in a fraction of the time it would take without AI assistance.
This framing resolves a persistent tension in AI product design. Rather than chasing the all-or-nothing goal of full autonomy—which leads to spectacular demos and fragile products—the Iron Man suit approach prioritizes building the autonomy slider and the generation-verification loop. The system becomes a partner that drafts, analyzes, and creates, but the human makes the final call. This leverages the LLM’s encyclopedic knowledge and speed while mitigating its jagged reasoning and propensity for confident errors.
For engineering leaders, the strategic choice is clear. Do not build systems designed to operate without humans. Build systems that make your best people ten times more effective. The human remains the source of judgment, creativity, and accountability. The AI provides the speed, recall, and tireless execution.
One of the most striking trends to emerge from the Software 3.0 era is “vibe coding”—a development approach where software is created by describing intent in natural language rather than writing syntax. The developer describes what they want, the AI generates the code, the developer runs it, observes the result, and refines their prompt. It is programming by intent, not by instruction.
The results have been remarkable. Projects that once took weeks can now be completed in days or hours. A developer with minimal web experience can use tools like Cursor and an LLM to build a full-stack application—frontend, backend, and integrations—entirely by describing the app in conversational language. The developer’s cognitive focus shifts from syntax and logic to intent and vision.
| Metric | Traditional Development | Vibe Coding |
| Development Speed | Weeks / Months | Hours / Days |
| Cognitive Focus | Syntax / Logic | Intent / Vision |
| Bottleneck | Coding / Execution | Deployment / Verification |
| Role of Developer | Producer | Manager / Conductor |
But vibe coding also exposes a new category of risk. Developers may ship code they do not fully understand, leading to undetected security vulnerabilities or subtle logic errors. The implementation gap persists: the AI can generate functional code rapidly, but the devops and integration work—API rate limits, deployment pipelines, domain configuration, payment gateways—still requires human expertise. As one practitioner observed after building a vibe-coded app: the code was the easiest part.
This tension points to a rebalancing of engineering value. In a world where everyone can generate code, the real differentiator becomes knowing what to build and how to make it robust. The ultimate value lies in judgment: evaluating AI output for correctness and security, and steering the system toward outcomes that work not just in demos but in production. “Vibe code cleanup” services have already emerged to audit and harden AI-generated code, signaling that the demand for expert review is growing, not shrinking.
All of these changes point to one fundamental truth: we have a new class of users, and our digital infrastructure was not designed for them. Until now, software was built for two audiences: people (who interact through GUIs) and machines (which communicate through APIs). Now we must also build for AI agents—entities that process information like machines but reason like humans.
Think of MCP as a USB-C port for AI applications. Instead of building custom plugins for every LLM-host and every tool, MCP provides a uniform RPC interface (typically JSON-RPC 2.0 with Server-Sent Events) that allows any AI agent to securely invoke external tools, databases, or services. Whether it is a desktop application or a cloud-hosted agent, they all speak MCP as a common language to interact with the outside world. MCP servers act as brokers, mediating access between the AI’s reasoning and sensitive resources—a critical security layer for enterprise deployments.
Another emerging standard is llms.txt, inspired by the robots.txt convention for web crawlers. This is a machine-readable file that websites serve to declare how AI agents should interact with their content—what is available, what requires authentication, and what actions can be triggered. Just as robots.txt helped web crawlers navigate the internet responsibly, llms.txt will help AI agents navigate the world’s services in a structured and authorized manner.
For senior engineers, this means a fundamental shift in documentation and service design. Documentation should focus on agent-executable commands (like cURL requests and structured API schemas) rather than click-through-the-GUI instructions. We must build for a world where an agent does not just read documentation but acts upon it. The host application becomes a security broker, mediating access between the AI’s reasoning and the external system’s resources.
This is the new frontier of infrastructure engineering. Building for agents is not a speculative exercise—it is the construction of a machine-readable layer on top of the world’s software, and the teams that build it first will define the architecture of the next decade.
If the analogy to computing history holds, we are standing in the 1960s of the AI operating system. The mainframes are here. The time-sharing model is operational. But the personal computers, the graphical user interfaces, and the killer applications are all waiting to be invented. The pioneers of computing’s 1960s built the protocols and kernels that define our digital lives today. We are now building the substrate for the next century of intelligence.
The monolithic, cloud-resident models of today will eventually give way to smaller, more personal, and more autonomous systems. But for now, the centralized mainframe model remains our primary tool, and the engineering task is to make it useful, safe, and robust.
The barrier between imagination and implementation has never been lower. The machine is finally listening, the syntax has become natural, and the story of Software 3.0 is ours to tell.
The mandate for engineering leaders is clear. Build with a partial autonomy mindset. Focus on the generation-verification loop. Design autonomy sliders that let users dial up AI assistance as trust is earned. Invest in MCP servers, llms.txt files, and fast-audit interfaces. Treat LLMs as powerful but untrusted collaborators that require human oversight.
We are living through a magnitude-9 earthquake in software engineering. The stack is being refactored at a fundamental level. But for those who embrace the three paradigms of software—code, weights, and prompts—this is the most exciting era in the history of our profession.
Go build something that understands us. The era of the AI-augmented builder has begun.