

The AI “jagged frontier” just moved again, and this time it didn’t come with a flashy keynote. OpenAI surprise-dropped GPT-5.5 (codenamed “Spud”), and the technical community is scrambling to figure out if this is a true step-change or just another incremental polish.
I’ve spent the last two hours ignoring the hype to focus on the signal. We are officially past the era where “counting the Rs in strawberry” or writing rhyming couplets are valid tests of frontier intelligence. My goal was simple: can this model actually do real, agentic computer work? Can it handle the messy, unstructured, “babysitting-required” tasks that have stalled every model before it?
The answer is yes—but the way you use it needs to change.
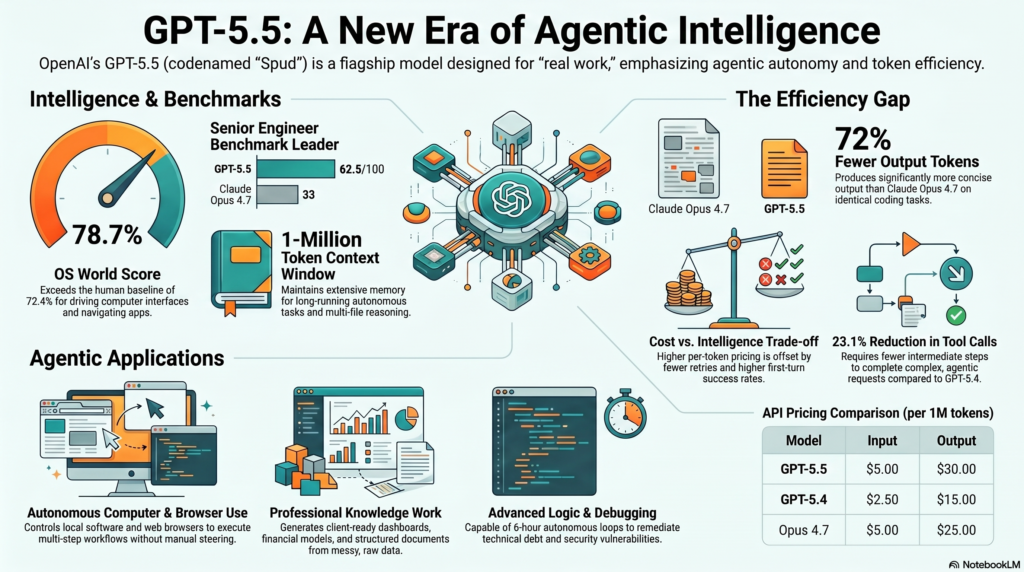
The most counter-intuitive finding comes from the MindStudio analysis: GPT-5.5 uses 72% fewer output tokens than Claude Opus 4.7 for identical coding tasks.
In the strategist’s world, this is a massive win for ROI. While OpenAI has doubled the per-token price, the total bill often ends up lower because the model isn’t “talking” as much. It generates tight, assertive diffs instead of narrating its life story.
“On the same coding tasks—identical prompts, identical goals—GPT-5.5 produces roughly 72% fewer output tokens than Claude Opus 4.7. That’s not a rounding error. It’s a structural difference in how each model communicates.” — MindStudio Analysis
This isn’t just about saving pennies; it’s about performance. Fewer tokens mean lower latency and a dramatic reduction in “context rot.” Verbose models fill their context windows with fluff, leading to degraded reasoning in long sessions. GPT-5.5 stays “fresh” by getting straight to the point.
In the “Senior Engineer Benchmark”—a test designed by the Every team to see if AI can rewrite “slop-coded” apps from first principles—GPT-5.5 hit a score of 62.5. For context, Claude Opus 4.7 landed in the low 30s. Human senior engineers reside in the 80–90 range.
However, there is a fascinating nuance here. GPT-5.5 is a world-class Operator, but Claude Opus 4.7 is still the superior Architect.
The Execution Beast Testing showed that GPT-5.5 performs significantly better when it executes a plan written by Claude Opus 4.7. Why? Because Opus is elite at “contract-driven” planning—identifying underlying core principles and invariants. GPT-5.5, meanwhile, has the “assertiveness” that Opus lacks; it will actually go in and delete redundant files or execute complex, hour-long refactors without getting distracted or slipping into “patch mode.”
We’ve all heard the promise of “AI agents running overnight,” but in practice, they usually require constant hand-holding. A case study from Clara Veo (How I AI) proves that GPT-5.5 has finally broken the “babysitting” barrier.
Veo tasked the model with a complex data migration involving two million rows of unstructured legacy data—a project plagued by endless edge cases. The result? A 6-hour autonomous run with zero follow-ups and zero steering. Out of those two million rows, the model caught all but one edge case.
This is the shift from “chat tool” to “persistent agent.” It is the end of the 15-minute feedback loop. You give it a triage list of technical debt or security gaps, and it bangs its head against the wall for half a workday until the problem is solved.
If you want proof of raw intelligence over benchmark gaming, look at Veo’s “Doom Mini2” experiment. This involves a proprietary, Chinese-language Bluetooth speaker with no public SDK.
Claude Opus 4.7 and GPT-5.4 both failed to figure out how to programmatically control the device’s screen. GPT-5.5, however, was fed raw logs from a Bluetooth packet sniffer. It successfully decoded the bitmap transport mechanism and wrote a command-line tool to display custom images on the hardware. That is “frontier intelligence”—solving a proprietary, undocumented hardware problem through pure reasoning.
The battle for AI dominance has moved from the chat box to the OS. When tested within the Codeex harness (OpenAI’s pro-tier desktop environment), GPT-5.5’s “Computer Use” capabilities are startling.
On the OS World benchmark—which requires an agent to click, type, and navigate a computer like a human—GPT-5.5 scored 78.7%, officially surpassing the human baseline of 72.4%. It demonstrates a level of spatial awareness in apps like Canva and Finder that makes previous models look blind.
“The great race going on between OpenAI and Anthropic is they’re trying to create the models and platforms to be able to control your browser and control your computer. That’s the greatest race.” — Riley Brown
OpenAI has effectively doubled the price of intelligence. Note that GPT-5.5 Pro is currently gated behind Pro, Business, and Enterprise plans.
| Model | Input (per 1M) | Output (per 1M) |
| GPT-5.4 | $2.50 | $15.00 |
| GPT-5.5 | $5.00 | $30.00 |
| GPT-5.5 Pro | $30.00 | $180.00 |
Is it worth it? For a power user, yes. If a model solves a problem in one shot with 72% fewer tokens, the “Intelligence Tax” is actually a discount. You are paying for fewer retries and lower total latency.
Using GPT-5.5 requires a mindset shift regarding time. Because of its heavy reasoning architecture, the model can spend upwards of 17 minutes “thinking” before it speaks.
Here is the strategic “signal”: if you use this model for a first-grade math app (as one tester did) and it spends 17 minutes thinking, you are witnessing a massive intelligence overhang. Using a superintelligence for basic logic is a waste of compute.
As for the “vibe,” the default personality is a “baked potato”—dull, flat, and robotic. However, the Codex app now includes a /personality command. You can toggle to a “Gen Z” persona that is friendlier, though some early testers found it a bit over-the-top.
GPT-5.5 is not an incremental update; it is a redefinition of “real work.” By surpassing the human baseline in computer use and demonstrating multi-hour autonomy, it has moved the frontier into the realm of sustained, independent execution.
As these models begin to drive our browsers and navigate our file systems better than we can, the strategic question changes. We are no longer asking if the AI can do the work, but why we are still giving it such small tasks. We are living in an era of “intelligence overhang,” where the capabilities of the model far exceed the complexity of the problems we are brave enough to assign them.
The frontier has moved. Have you?